
This article describes how to use UiPath’s OCR to extract text data from PDF files.
\Save during the sale period!/
Take a look at the UiPath course on the online learning service Udemy
*Free video available

Japanese IT engineer with a wide range of experience in system development, cloud building, and service planning. In this blog, I will share my know-how on UiPath and certification. profile detail / twitter:@fpen17
This site was created by translating a blog created in Japanese into English using the DeepL translation.
Please forgive me if some of the English text is a little strange
Get OCR Text
To read text data in PDF files with OCR, use Get OCR Text and the OCR engine.
Get OCR Text setting items
| Setup Location | Setting items | Configuration details |
|---|---|---|
| Output | Text | The string extracted from the indicated UI element. |
| WordsInfo | The screen coordinates of each word found in the indicated UI element. | |
| Misc | Private | If selected, the values of variables and arguments are no longer logged at Verbose level. |
| Target.Selector | ext property used to find a particular UI element when the activity is executed. | |
| Target.TimeoutMS | Specifies the amount of time (in milliseconds) to wait for the activity to run before the SelectorNotFoundException error is thrown. | |
| Target.WaitForReady | Before performing the actions, wait for the target to become ready. | |
| Target.Element | Use the UiElement variable returned by another activity. | |
| Target.ClippingRegion | Defines the clipping rectangle, in pixels, relative to the UiElement, in the following directions: left, top, right, bottom. | |
| Common | DisplayName | The display name of the activity. |
| ContinueOnError | Specifies if the automation should continue even when the activity throws an error. |
Uses Tesseract OCR as engine
Reads PDF files with the OCR engine as Tesseract OCR.
Tesseract OCR configuration items
| Setup Location | Setting items | Configuration details |
|---|---|---|
| Options | AllowedCharacters | The OCR engine extracts the given string according to the characters specified here. |
| DeniedCharacters | The OCR engine extracts the given string without taking into account the characters specified here. | |
| Invert | If this check box is selected, the colors of the UI element are inverted before scraping. | |
| Language | The language used by the OCR engine to extract the string from the UI element. | |
| ExtractWords | If this check box is selected, the on-screen position of each detected word is extracted. | |
| Profile | Choose a preprocessing profile for the specified image or UI element to achieve a better OCR read. | |
| Scale | The scaling factor of the selected UI element or image. | |
| Output | Text | The extracted string. |
| Result | The extracted words along with their on-screen position. | |
| Input | Image | The image that you want to process. |
| Common | DisplayName | The display name of the activity. |
| Misc | Private | If selected, the values of variables and arguments are no longer logged at Verbose level. |
sample process
Read PDF text and output to log
– workflow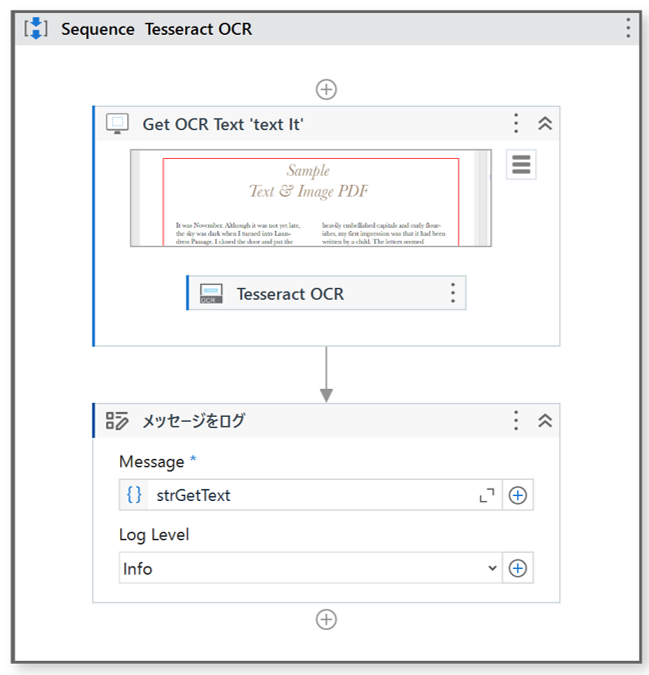
– Target PDF
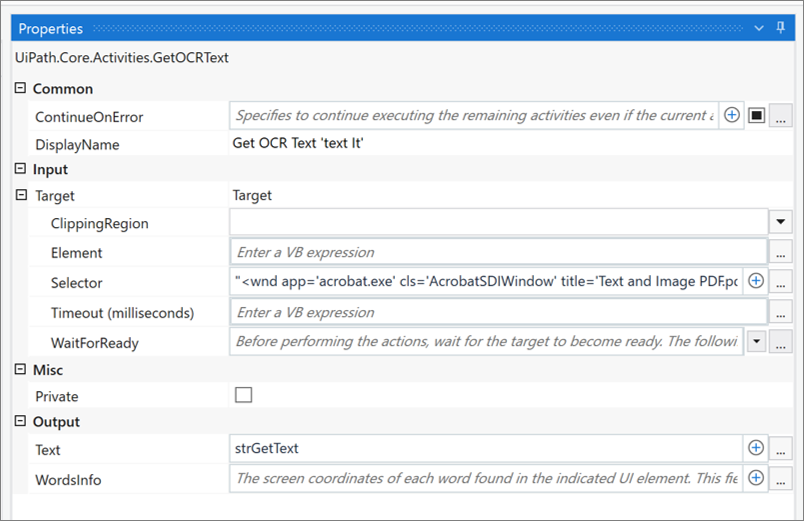
– Properties of “Get OCR Text ‘text It'”.
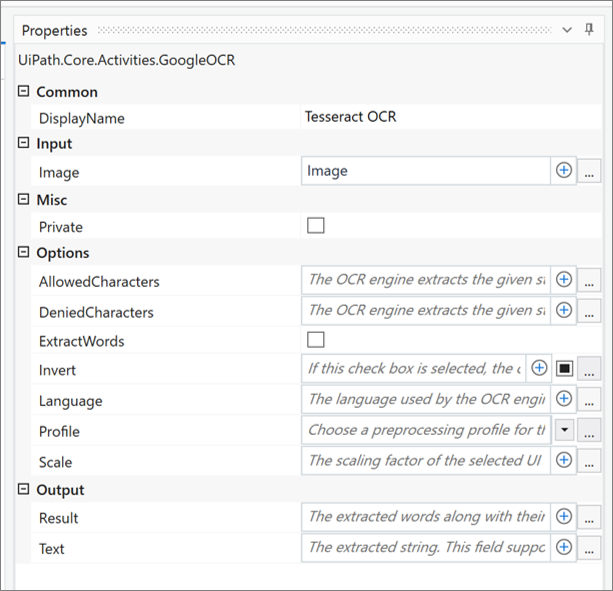
– Properties of “Tesseract OCR”
– variable
– Execution Result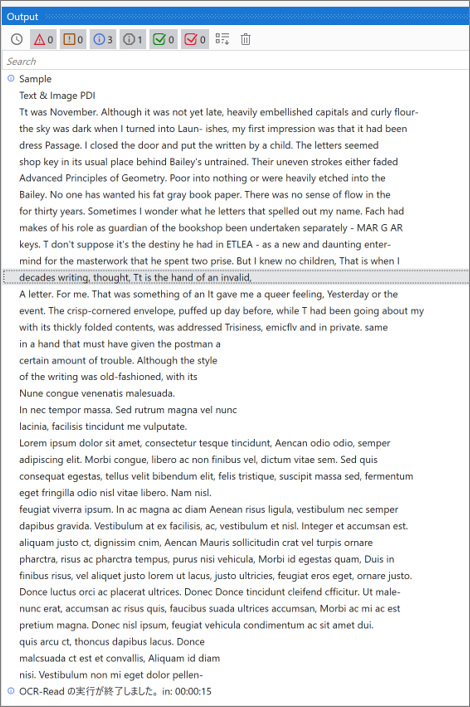

I’m able to output PDF text to the log.
Use UiPath Screen OCR as engine
Reads PDF files with the OCR engine as “UiPath Screen OCR”.
UiPath screen OCR setting items
| Setup Location | Setting items | Configuration details |
|---|---|---|
| Common | DisplayName | The display name of the activity. |
| Input | Image | The image that you want to process. |
| Logon | ApiKey | The API key used to provide you access to the UiPath Screen OCR (not required for the Preview period). |
| Endpoint | The endpoint for UiPath Screen OCR. The default project settings value is https://ocr.uipath.com/. | |
| Timeout (milliseconds) | Specifies the amount of time (in milliseconds) to wait for a response from the server before an error is thrown. | |
| Misc | Private | If selected, the values of variables and arguments are no longer logged at Verbose level. |
| UseLocalServer | Determines if a local server should be used. | |
| Output | Result | Provides the extracted words along with their on-screen position. |
| Text | Provides the extracted text. |
sample process
Reads PDF text and outputs it to the log
– workflow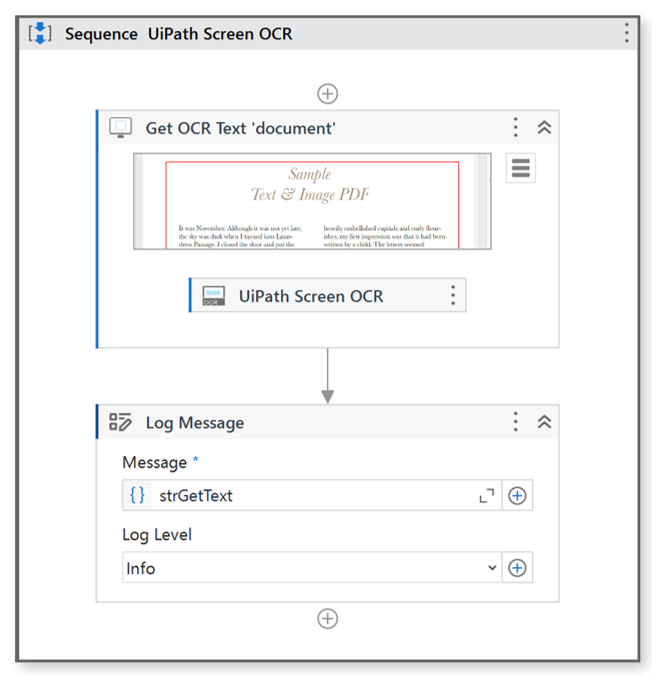
・Get OCR Text ‘document’ Properties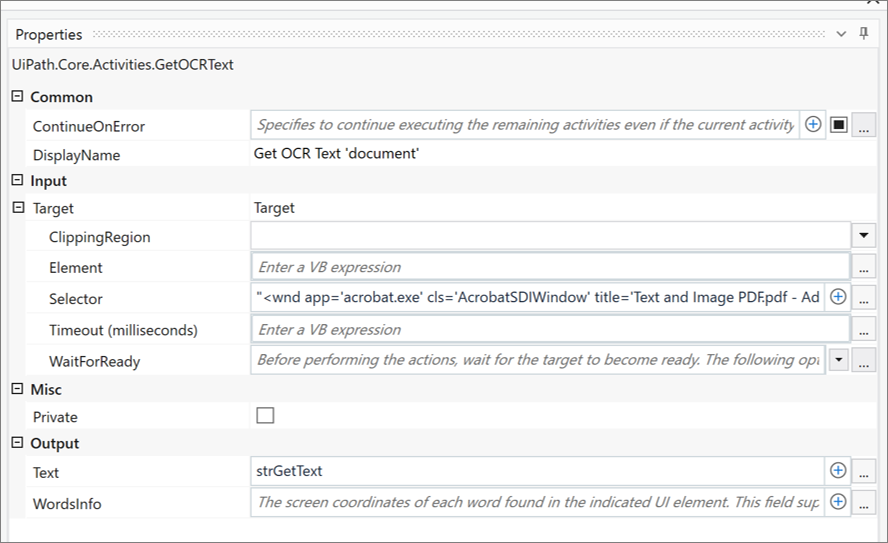
– UiPath Screen OCR Properties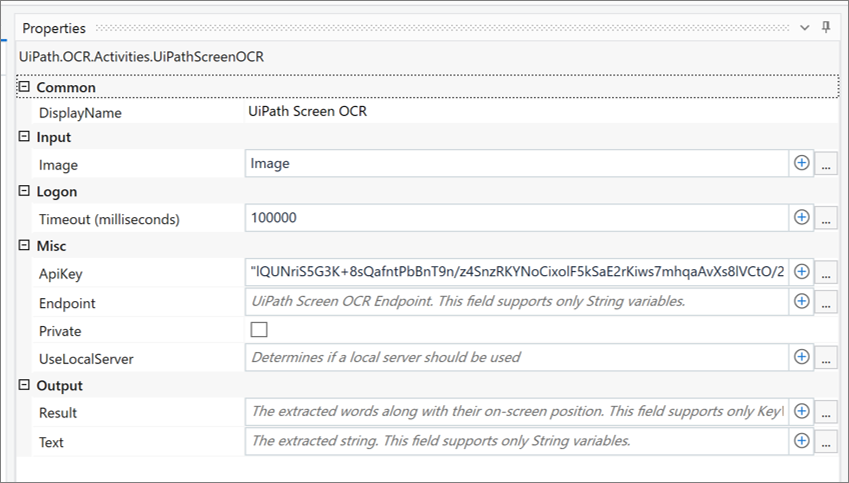
– variable

– PDF to be read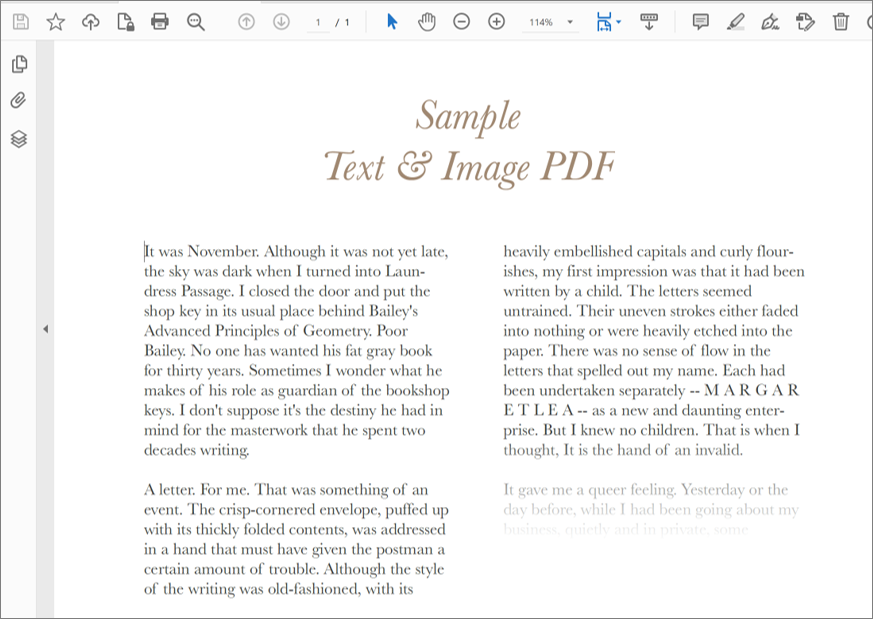
– Execution Result Log
I’m able to output PDF text to the log.
Uses OCR for Chinese, Japanese and Korean as engine
Read PDF files with OCR engine as OCR – Japanese, Chinese, Korean
OCR for Chinese, Japanese and Korean settings
| Setup Location | Setting items | Configuration details |
|---|---|---|
| Common | DisplayName | The display name of the activity. |
| Input | Image | The image that you want to process. |
| Logon | ApiKey | The API key used to provide you access to Document Understanding, when the OCR for Chinese, Japanese and Korean is used with Document Understanding activities. |
| Endpoint | The endpoint associated with your Document Understanding API key. | |
| Misc | Private | If selected, the values of variables and arguments are no longer logged at Verbose level. |
| Output | Result | rovides the extracted words and information about their position on the screen. |
| Text | Provides the extracted text. This field supports only String variables. |
sample process
Reads PDF text and outputs it to the log.
– workflow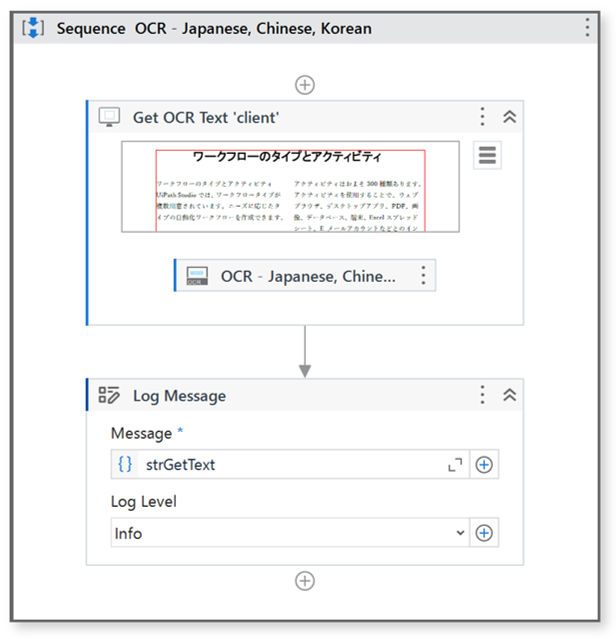
・Get OCR Text ‘client’ Properties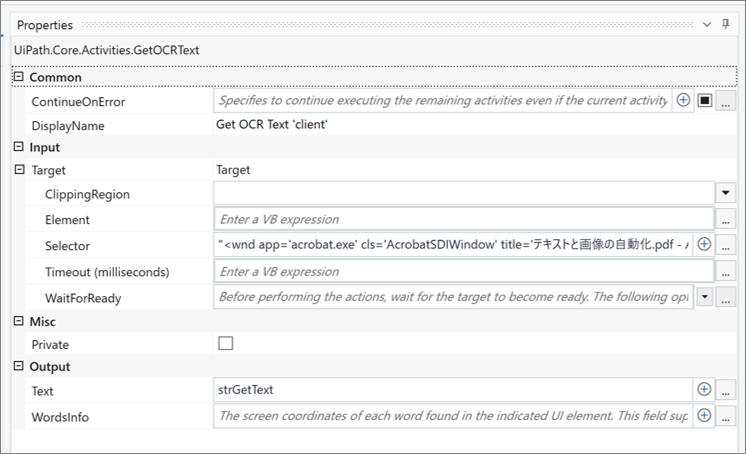
– OCR – Japanese, Chinese, Korean Properties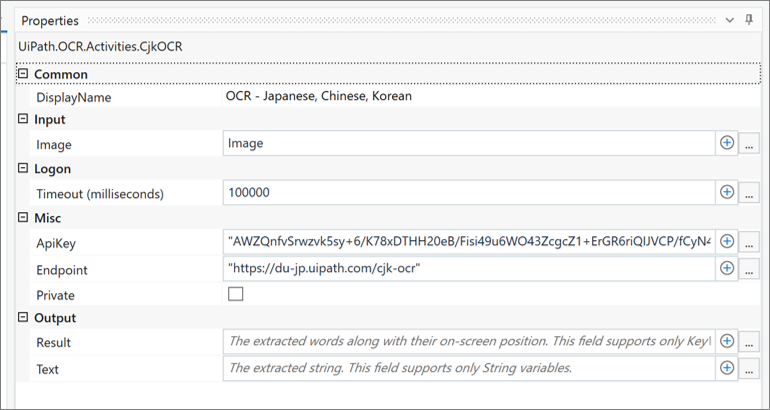

To obtain an API key, go to “Admin → Licenses → Robots & Service → Computer Vision” in Automation Cloud and click on “Api Key”.
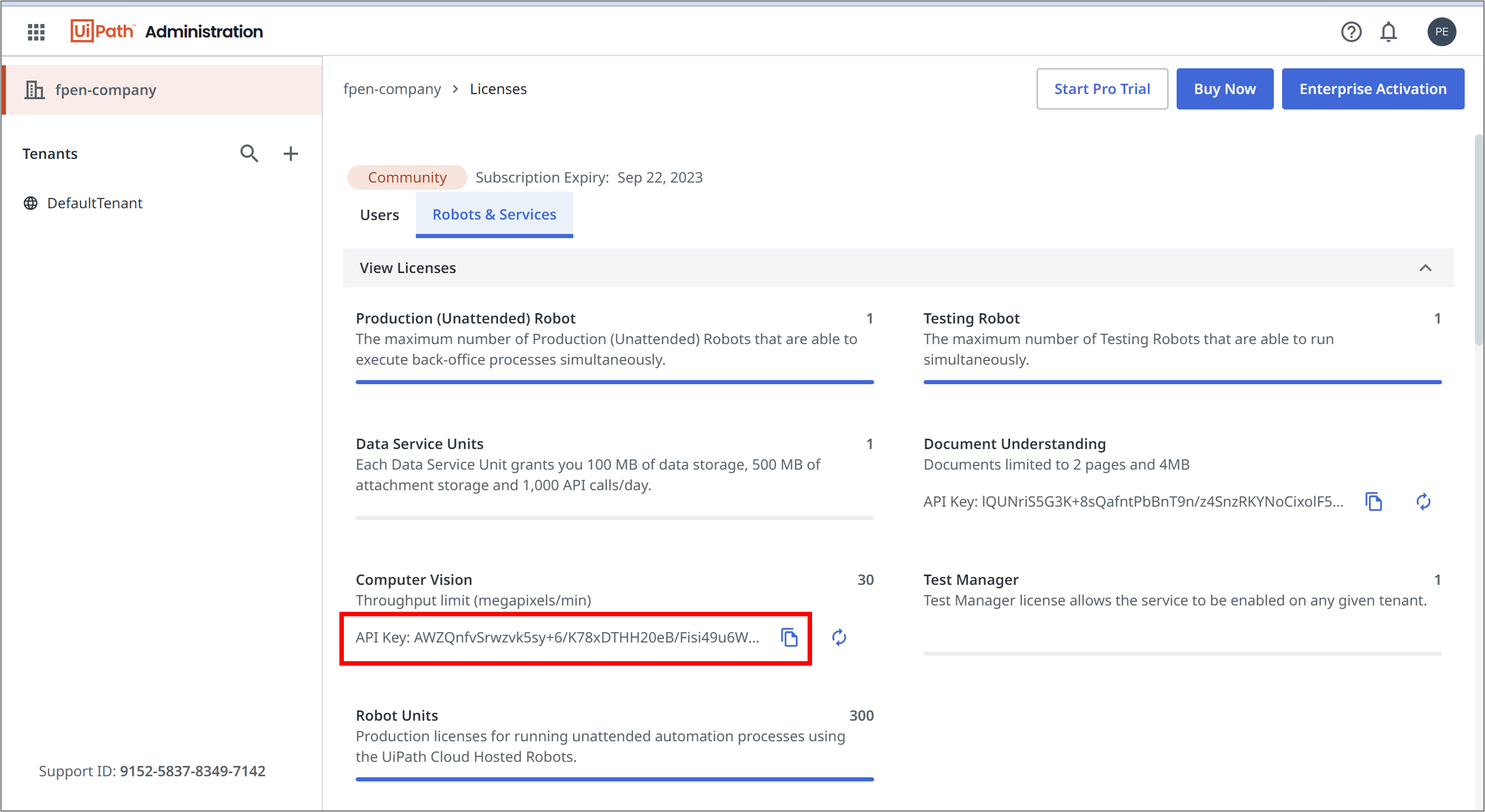
– variable
– PDF to be read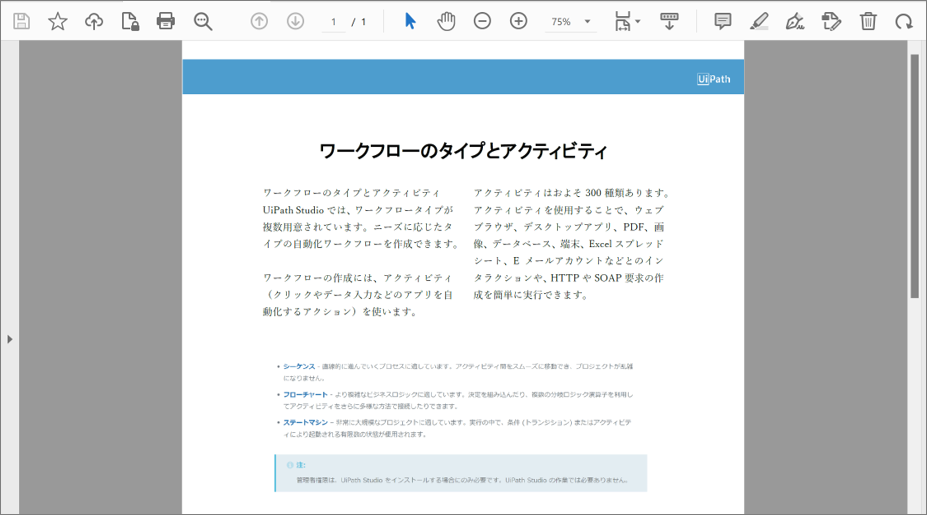
– Execution Result Log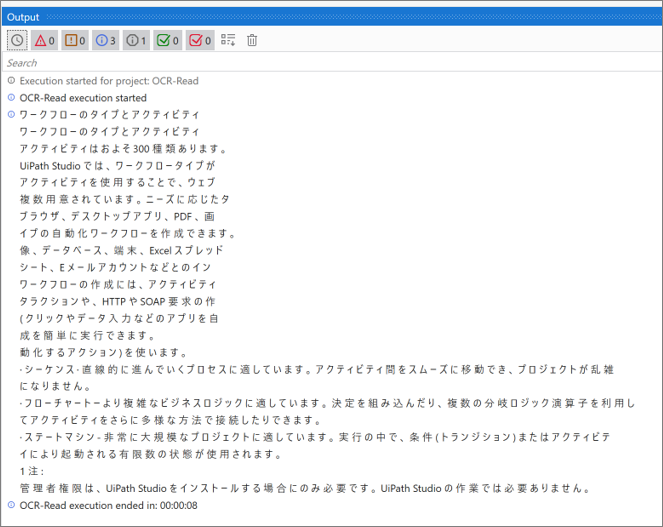
I’m able to output PDF text to the log
Summary
- Get OCR Text and read PDF text using one engine.
- For reading Japanese, use OCR – Chinese, Japanese, Korean.
\Save during the sale period!/
Take a look at the UiPath course on the online learning service Udemy
*Free video available







