
UiPath Studioの開発では、PDFファイルのテキスト取得して、システムへのデータ登録やメールの送信に利用したい場合があります。
この記事では、PDFパッケージのインストール方法、PDFアクティビティで出来ること、PDFのテキストデータの抽出方法について、解説します。
関連記事 【UiPath】Udemyのオンラインコースでワンランク上のロボット作成技術を学ぶ

システム開発,クラウド構築,サービス企画まで幅広い経験を持つITエンジニア。当ブログでは、UiPathや資格取得のノウハウを発信します。profile詳細 / twitter:@fpen17
PDFパッケージインストール手順
PDFのテキスト読み込みやPDFのページ数の取得するアクティビティは、PDFのアクティビティパッケージ(UiPath.PDF Activities)をインストールする必要があります。
アクティビティパッケージは、プロセスごとに設定されるので、新しいプロセスを作成するたびに必要に応じてインストールします。
PDFパッケージのインストール手順
①対象のプロセスをStudioで開いた状態で、[パッケージを管理]をクリックする
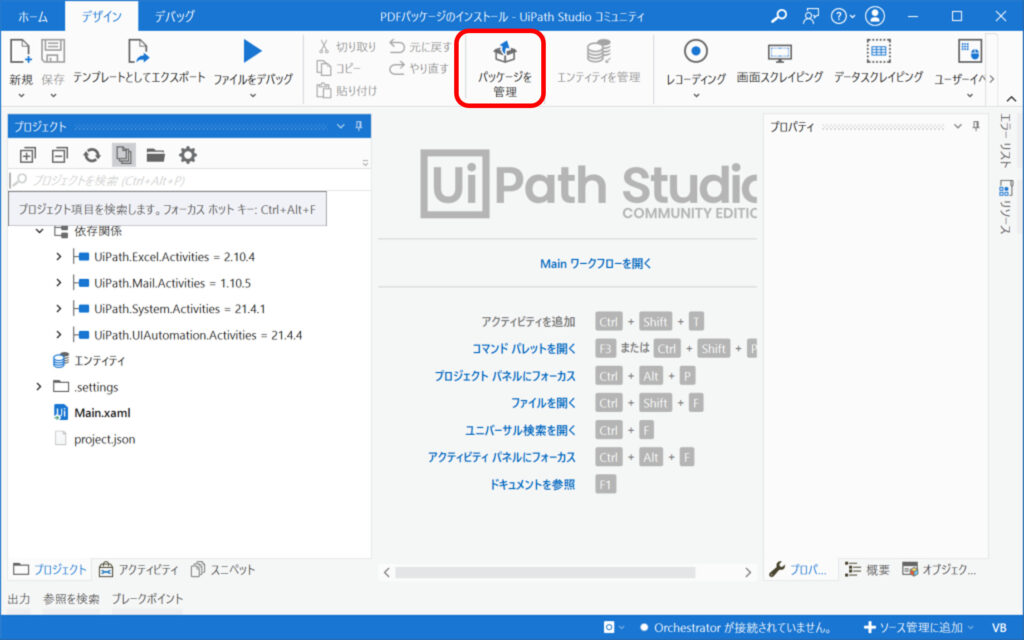
②ポップアップされた画面の[オフィシャル]をクリックする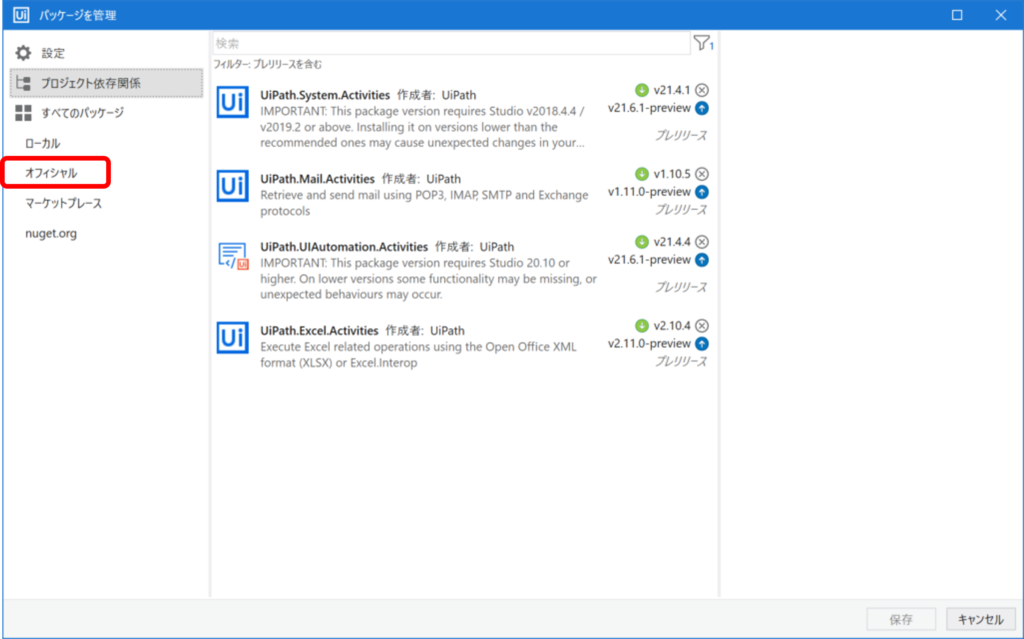
③検索窓に「PDF」を入力し、[UiPath.PDF Activities]をクリックする
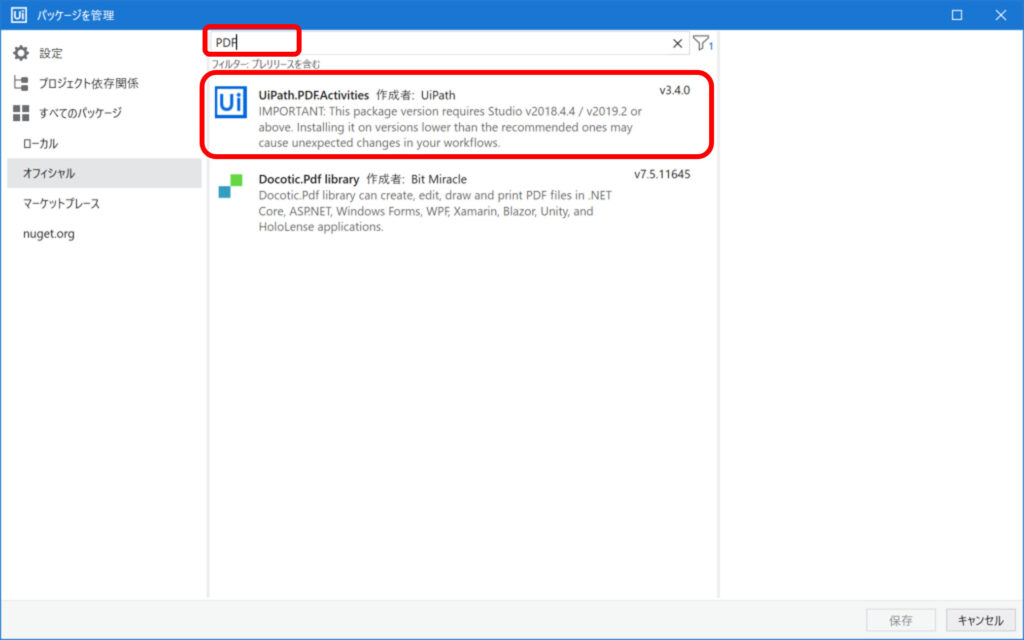
④[インストール]をクリックする
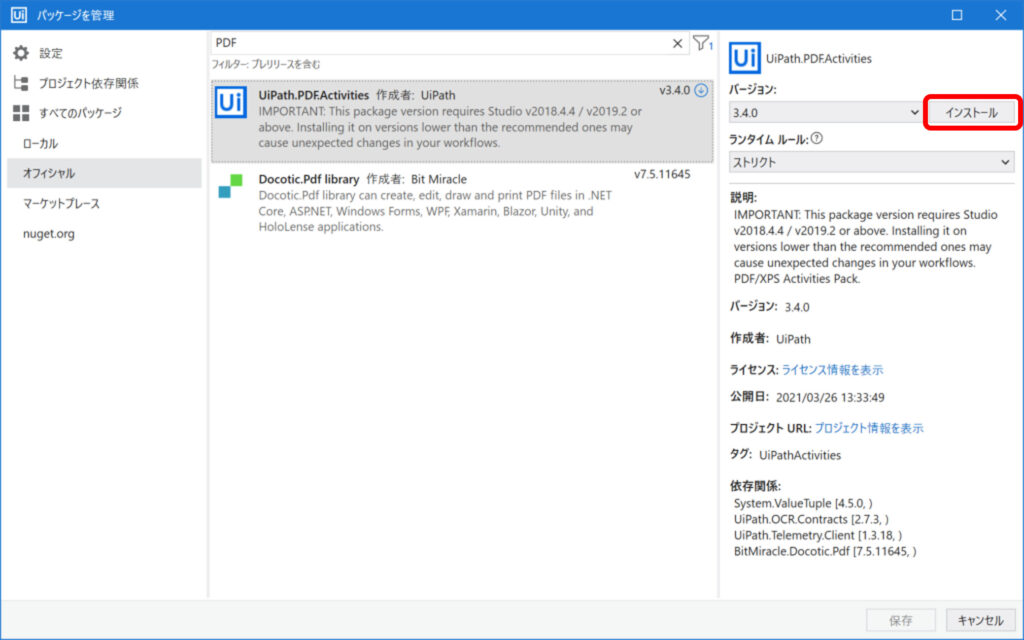
⑤[保存]をクリックする
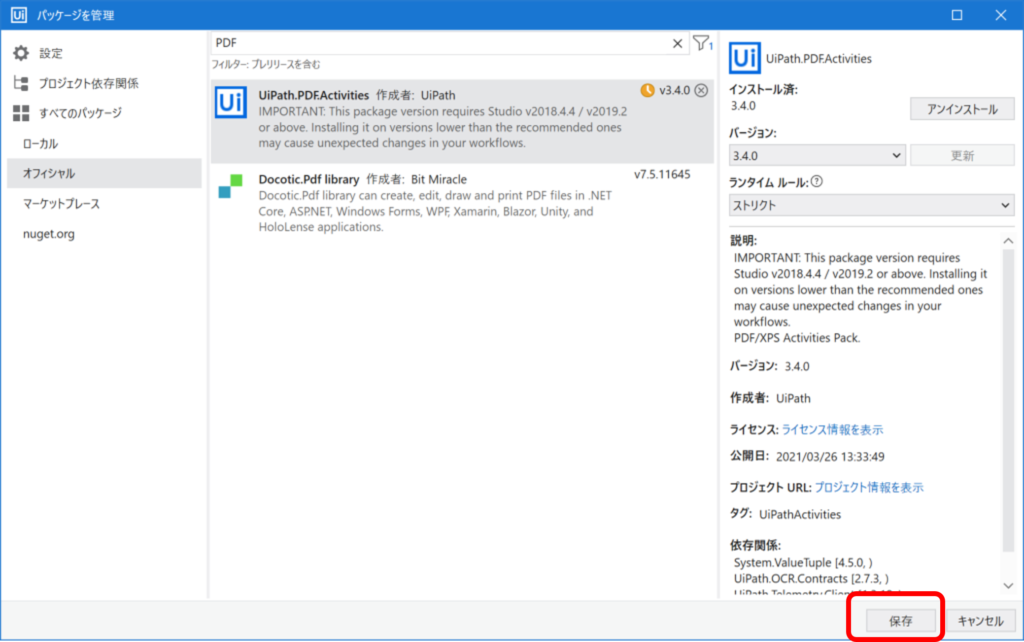
⑥左下の[プロジェクト]をクリックし、UiPath.PDF Activitiesが表示されていることを確認する
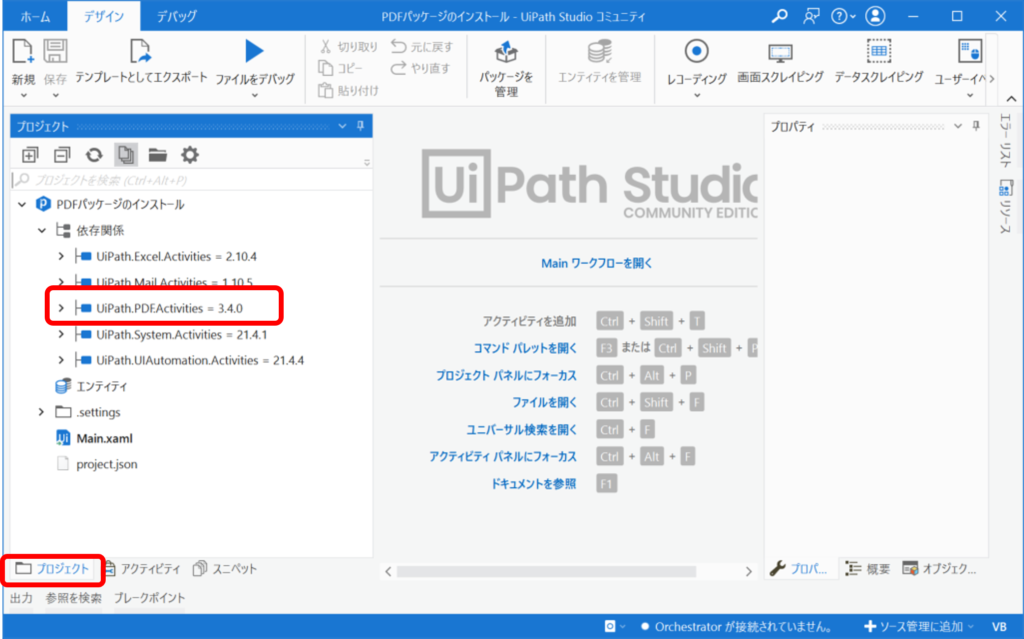
PDFアクティビティでできること
PDFのアクティビティパッケージをインストールすることで、テキスト読み取りや画像を作成するアクティビティを使用できます。
PDFアクティビティは、 アプリの連携 > PDF にあります。
PDFアクティビティ
| アクティビティ名 | アクティビティの動作 |
| OCR で PDF を読み込み (Read PDF With OCR) | OCR テクノロジーを使用して、指定した PDF ファイルからすべての文字を読み取り、String 型変数に格納します。 |
| PDF から画像を抽出 (Extract Images From PDF) | 指定した PDF ファイルから画像を抽出します。 |
| PDF のテキストを読み込み (Read PDF Text) | 指定した PDF ファイルからすべての文字を読み取り、String 型変数に格納します。 |
| PDF のパスワードを管理 (Manage PDF Password) | 指定した PDF ファイルのパスワードを変更します。 |
| PDF のページ数を取得 (Get PDF Page Count) | PDF ファイルの総ページ数を指定します。 |
| PDF のページ範囲を抽出 (Extract PDF Page Range) | PDF ドキュメントの指定したページ範囲を抽出します。 |
| PDF ファイルを結合 (Join PDF Files) | 文字列の配列で格納されている複数の PDFファイルを単一の PDF ファイルに結合します。 |
| PDF ページを画像としてエクスポート (Export PDF Page As Image) | 指定した PDF ファイルのページから画像を作成します。 |
PDFファイルの全テキストデータ抽出
PDFファイル内の全テキストの抽出は、PDFのテキストを読み込み、フルテキストを取得 、OCRでPDFを読み込み のアクティビティを使用します。
PDFの全テキストを抽出するアクティビティ
| アクティビティ名 | アクティビティの場所 | アクティビティの概要 | 読み取り精度 |
| PDF のテキストを読み込み | アプリの連携 > PDF | 指定した PDF ファイルからすべての文字を読み取り、String 型変数に格納します。 | △ |
| フルテキストを取得 | UI Automation > テキスト > 画面スクレイピング | フルテキストの画面スクレイピング メソッドで、指定した UI 要素から文字列とその情報を抽出します。 | △ |
| OCR で PDF を読み込み | アプリの連携 > PDF | OCR テクノロジーを使用して、指定した PDF ファイルからすべての文字を読み取り、String 型変数に格納します。 | ×~△ (使用するOCRによる) |

PDFのテキストを読み込み (Read PDF Text)
PDFファイルのすべての文字を読み取るのは、「PDFのテキストを読み込み (Read PDF Text)」のアクティビティを使用します。
「PDFのテキストを読み込み (Read PDF Text)」は、System> Activities> Statements にあります。
PDF のテキストを読み込みの設定項目
| 設定場所 | 設定項目 | 設定内容 | |
| [プロパティ] パネル内 | ファイル (File) | ファイル名 | 読み込む PDF ファイルのパスです。 |
| パスワード | PDF ファイルのパスワードです (必要な場合) | ||
|
入力
|
書式を保持 | 選択されていると、このオプションは抽出が完了した後、ファイルの書式設定を維持します。 | |
| 範囲 | 読み取るページの範囲。 | ||
|
出力
|
テキスト | 抽出した文字列です。 | |
|
共通
|
表示名 | アクティビティの表示名です。 | |
|
その他
|
プライベート | オンにした場合、変数および引数の値が Verbose レベルでログに出力されなくなります。 | |
サンプルプロセス
PDFファイルの全テキストを読み取り、読み取ったテキストデータをログメッセージへ出力する。
・プロセス
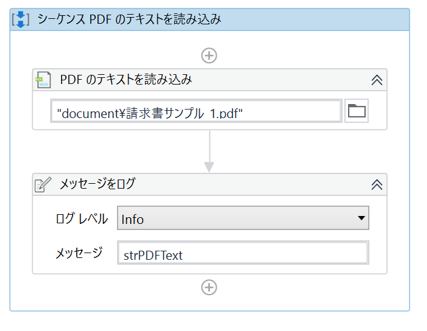
・「PDF のテキストを読み込み」のプロパティ
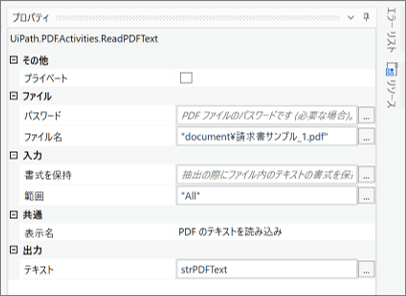
・変数のプロパティ

・読み込み対象のPDF(エクセルファイルのエクスポート、手書きなし)
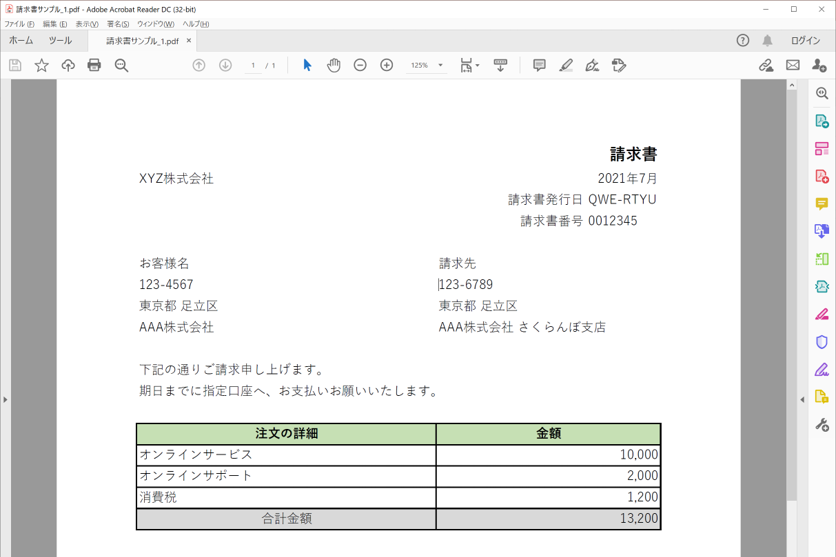
・実行結果
フルテキストを取得 (Get Full Text)
指定した UI 要素をPDFファイルを指定して、PDFファイルのテキストの文字を読み取るのは、「フルテキストを取得 (Get Full Text)」のアクティビティを使用します。
フル テキストを取得は、PDFファイルを開いた状態のセレクタを指定するので、Adobe Acrobat Reader(もしくは代替製品のPDFビューア) をインストールしておく必要があります。
フル テキストを取得 は、UI Automation > テキスト > 画面スクレイピング にあります。
フルテキストを取得を読み込みの設定項目
| 設定場所 | 設定項目 | 設定内容 | |
| [プロパティ] パネル内 | 出力 | テキスト | 指定した UI 要素から抽出された文字列です。 |
| オプション | 非表示を無視 | このチェック ボックスをオンにした場合は、指定した UI 要素の文字列情報が抽出されません。 | |
| その他 | プライベート | オンにした場合、変数および引数の値が Verbose レベルでログに出力されなくなります。 | |
| セレクタ | ターゲット | アクティビティの実行時に特定の UI 要素の検索に使用する Text プロパティです。 | |
| タイムアウト(ミリ秒) | エラーがスローされる前にアクティビティが実行されるまで待機する時間 (ミリ秒単位) を指定します。 | ||
| 準備完了まで待機 | アクションを実行する前に、ターゲットが準備完了になるまで待ちます。 | ||
| 要素 | 別のアクティビティから返される UiElement 変数を使用します。 | ||
| クリッピング領域 | UiElement を基準とし、左、上、右、下の方向で、クリッピング四角形 (ピクセル単位) を定義します。 | ||
| 共通 | 表示名 | アクティビティの表示名です。 | |
| エラー発生時に実行を継続 | アクティビティが例外をスローした場合でも、ワークフローを継続するかどうかを指定します。 | ||
サンプルプロセス
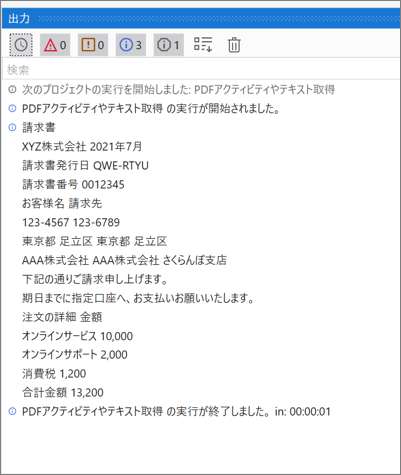
あらかじめ開いておいたPDFファイルのUI要素を指定して全テキストを読み取り、読み取ったテキストデータをログメッセージへ出力する。
・プロセス
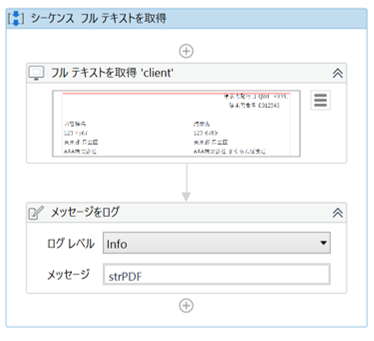
・フルテキストを取得のプロパティ
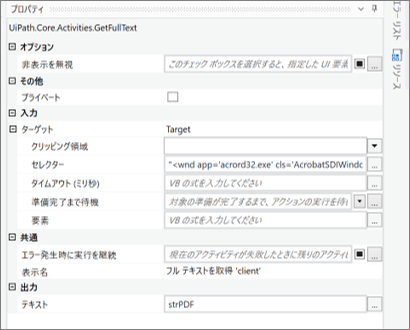
・フルテキストを取得のセレクタ
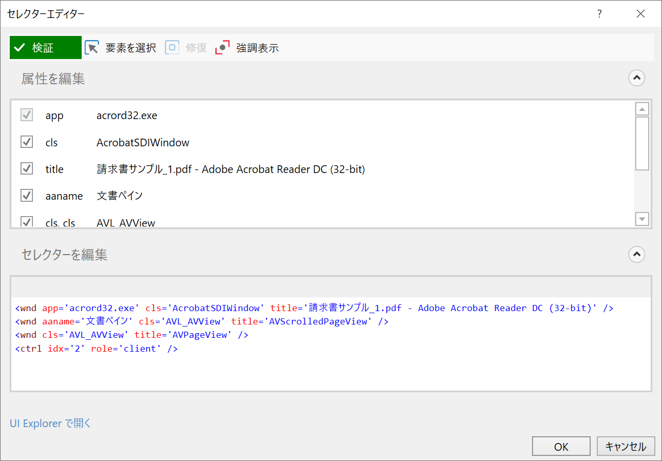
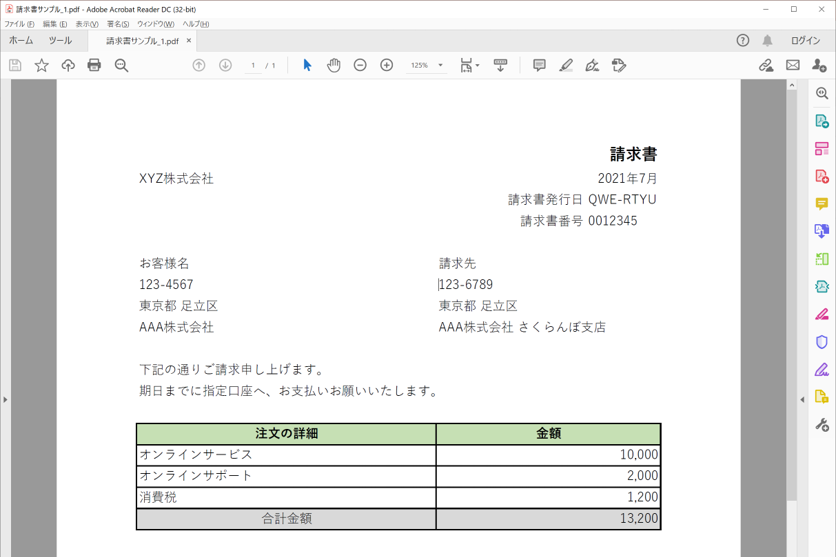
・読み取り対象のPDFファイル
・実行結果のログ

OCRでPDF を読み込み (Read PDF With OCR)
OCRでPDFファイルのすべての文字を読み取るのは、「OCRでPDF を読み込み (Read PDF With OCR)」のアクティビティを使用します。
「OCRでPDF を読み込み (Read PDF With OCR)」は、アプリの連携 > PDF にあります。
OCRでPDF を読み込みの設定項目
| 設定場所 | 設定項目 | 設定内容 | |
| [プロパティ] パネル内 | 共通 | 表示名 | アクティビティの表示名です。 |
| ファイル | ファイル名 | 読み込む PDF ファイルのパスです。 | |
| パスワード | PDF ファイルのパスワードです (必要な場合)。 | ||
| 入力 | 並列度 | 並列で分析するページ数を指定します (該当する場合)。 | |
| 画像 DPI | OCR 処理で使用する DPI です。 | ||
| 範囲 | 読み取るページの範囲。 | ||
| その他 | プライベート | オンにした場合、変数および引数の値が Verbose レベルでログに出力されなくなります。 | |
| 出力 | テキスト | 抽出した文字列です。 | |
Tesseract OCRの追加設定手順
Tesseract OCR(旧Google OCR)は日本語の言語ファイルを、指定フォルダへ配置する必要があります。具体的な手順は以下の通りです。
①tesseract-ocr/tessdata のページで、jpn.traineddata をダウンロードする。
②UiPath のインストール ディレクトリ(※)に 「tessdata」 フォルダーを作成し、jpn.traineddataファイルを保存します。
③UiPath を再起動(アプリケーションを一度閉じてから起動)すると、日本語を使用できるようになります。
サンプルプロセス1
Microsoft OCRでPDFファイルの全テキストを読み取り、読み取ったテキストデータをログメッセージへ出力する。
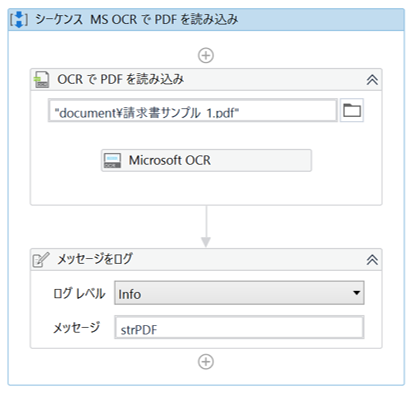
・「OCR で PDF を読み込み」のプロパティ
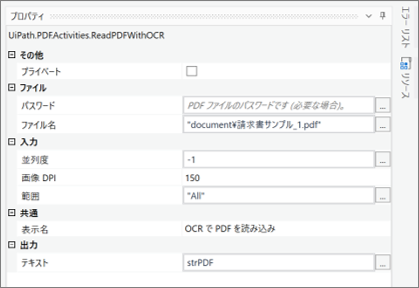
・「Microsoft OCR」のプロパティ
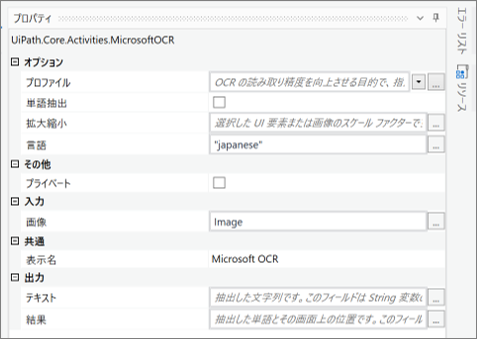
・変数のプロパティ

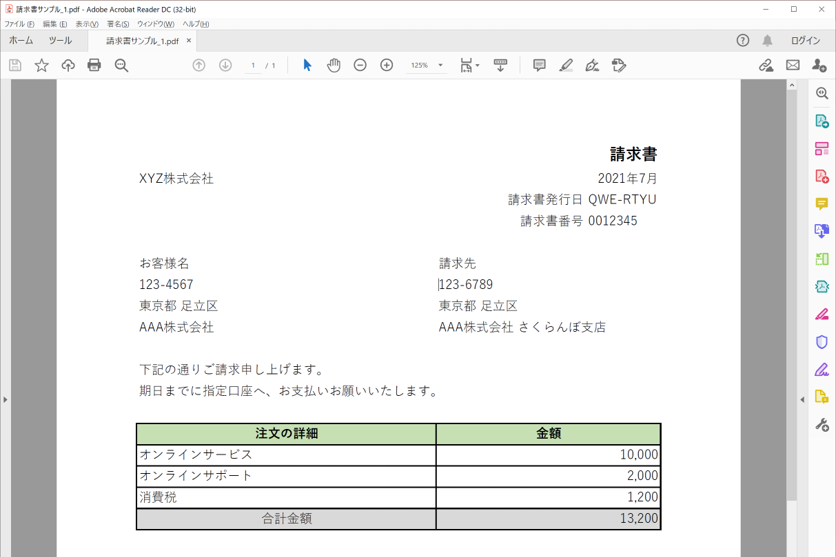
・読み取り対象のPDF
・実行結果のログ
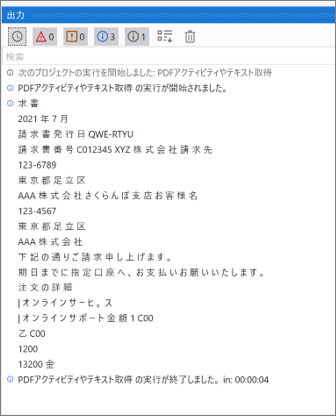
サンプルプロセス2
Tesseract OCRでPDFファイルの全テキストを読み取り、読み取ったテキストデータをログメッセージへ出力する。
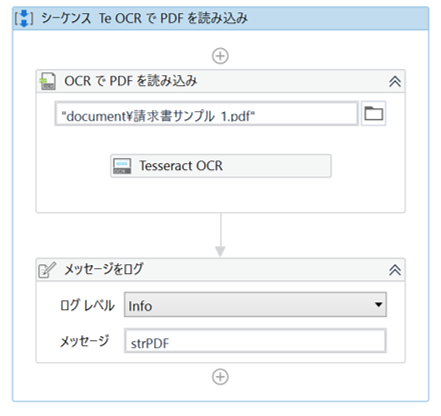
・「OCR で PDF を読み込み」のプロパティ
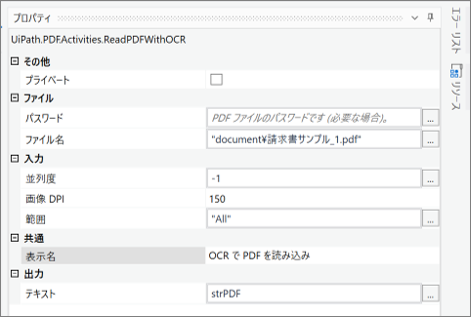
・「Tesseract OCR」のプロパティ
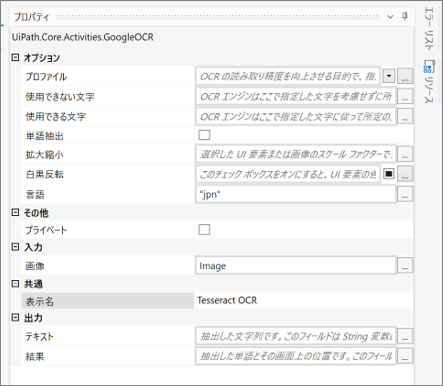
・変数のプロパティ

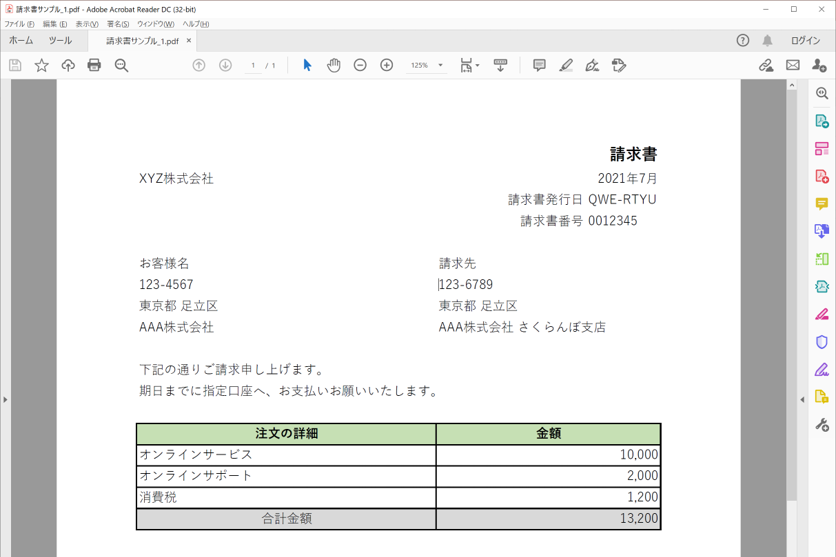
・読み取り対象のPDF
・実行結果のログ
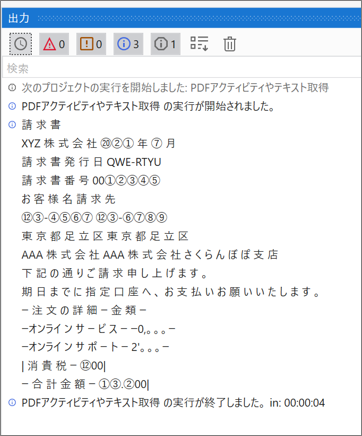
PDFファイルの一部テキストデータ抽出
PDFファイル内の一部テキストの抽出は、テキストの取得、表示中のテキストを取得、アンカーベース、CV テキストを取得のアクティビティを使用します。
PDFの一部テキストを抽出するアクティビティ
| アクティビティ名 | アクティビティの場所 | アクティビティの概要 | 読み取り精度 |
| テキストを取得 | UI AUtomation > 要素 > 制御 | 指定した UI 要素からテキスト値を抽出します。 | △ |
| 表示中のテキストを取得 | UI AUtomation > テキスト > 画面スクレイピング | Native 画面スクレイピング メソッドを使用して、指定した UI 要素から文字列とその情報を抽出します。 | △ |
| アンカーベース | UI AUtomation > 要素 > 検出 | 他の UI 要素をアンカーとして使用して UI 要素を検索するコンテナーです。 | △ |
| CV テキストを取得 | Computer Vision | UiPath Computer Visionニューラルネットワークを使用して、指定されたUI要素からテキストを抽出します。 | △ |
テキストを取得 (Get Text)
PDFの指定したUI 要素から一部のテキスト値を抽出するのは、「テキストを取得 (Get Text)」のアクティビティを使用します。
「テキストを取得 (Get Text)」は、 UI AUtomation > 要素 > 制御 にあります。
テキストを取得の設定項目
| 設定場所 | 設定項目 | 設定内容 | |
| [プロパティ] パネル内 | 出力 | 値 | 指定した UI 要素から抽出したテキストを変数に格納できます。 |
| 共通 | 表示名 | アクティビティの表示名です。 | |
| エラー発生時に実行を継続 | アクティビティが例外をスローした場合でも、ワークフローを継続するかどうかを指定します。 | ||
| その他 | プライベート | オンにした場合、変数および引数の値が Verbose レベルでログに出力されなくなります。 | |
| ターゲット | セレクタ | アクティビティの実行時に特定の UI 要素の検索に使用する Text プロパティです。 | |
| タイムアウト(ミリ秒) | エラーがスローされる前にアクティビティが実行されるまで待機する時間 (ミリ秒単位) を指定します。 | ||
| 準備完了まで待機 | アクションを実行する前に、ターゲットが準備完了になるまで待ちます。 | ||
| 要素 | 別のアクティビティから返される UiElement 変数を使用します。 | ||
| クリッピング領域 | UiElement を基準とし、左、上、右、下の方向で、クリッピング四角形 (ピクセル単位) を定義します。 | ||
サンプルプロセス
あらかじめ開いておいたPDFファイルのUI要素を指定して一部テキストを読み取り、読み取ったテキストデータをログメッセージへ出力する。
・プロセス
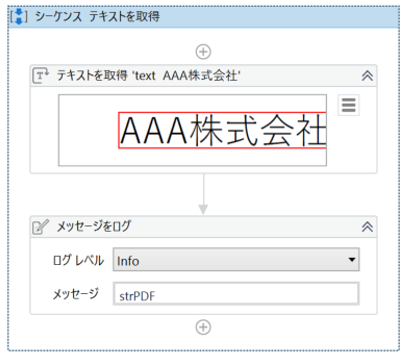
・「テキストを取得」のプロパティ
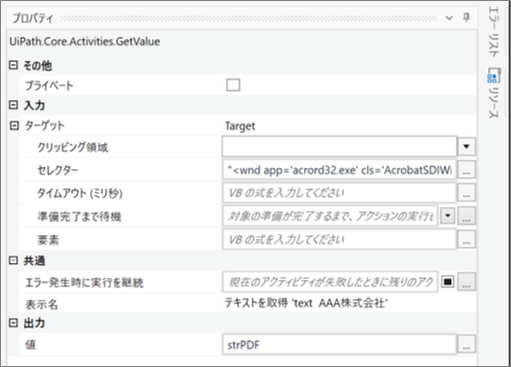
・「テキストを取得」のセレクタ
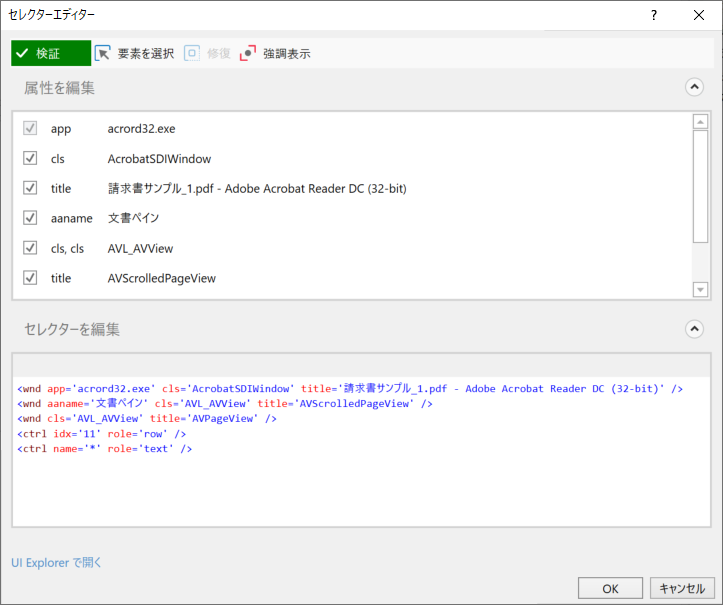
・変数の設定

・読み取り対象のPDF
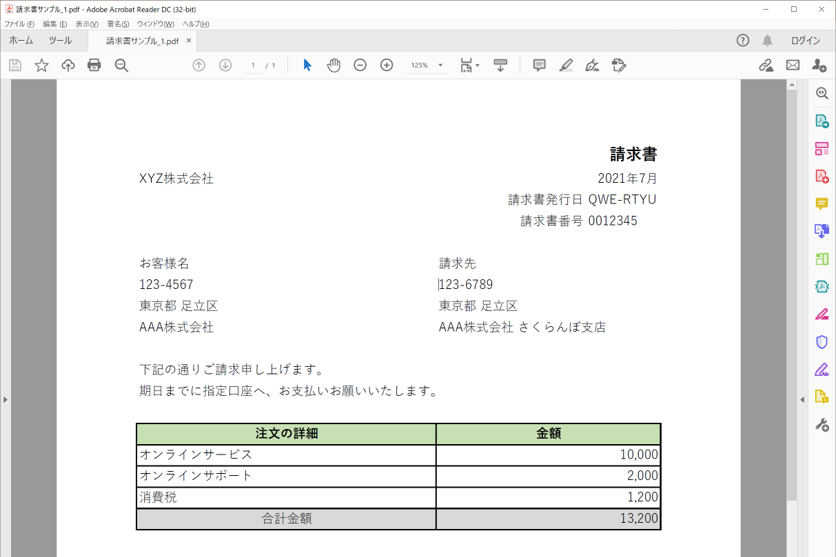
・実行結果のログ
表示中のテキストを取得 (Get Visible Text)
Native 画面スクレイピング メソッドを使用して、PDFから指定した UI 要素から文字列とその情報を抽出するのは、「表示中のテキストを取得 (Get Visible Text)」のアクティビティを使用します。
「表示中のテキストを取得 (Get Visible Text)」は、UI AUtomation > テキスト > 画面スクレイピング にあります。
表示中のテキストを取得の設定項目
| 設定場所 | 設定項目 | 設定内容 | |
| [プロパティ] パネル内 | 出力 | テキスト | 指定した UI 要素から抽出された文字列です。 |
| 単語情報 | 指定した UI 要素の中で見つかった各単語のスクリーン座標です。 | ||
| オプション | 区切り文字 | 文字列 (単語) を区切る文字を指定します。 | |
| 書式付きテキスト | このチェック ボックスをオンにした場合、スクレイピングしたテキストの画面レイアウトが保持されます。 | ||
| その他 | プライベート | オンにした場合、変数および引数の値が Verbose レベルでログに出力されなくなります。 | |
| 入力 | セレクター | アクティビティの実行時に特定の UI 要素の検索に使用する Text プロパティです。 | |
| タイムアウト(ミリ秒) | エラーがスローされる前にアクティビティが実行されるまで待機する時間 (ミリ秒単位) を指定します。 | ||
| 準備完了まで待機 | アクションを実行する前に、ターゲットが準備完了になるまで待ちます。 | ||
| 要素 | 別のアクティビティから返される UiElement 変数を使用します。 | ||
| クリッピング領域 | UiElement を基準とし、左、上、右、下の方向で、クリッピング四角形 (ピクセル単位) を定義します。 | ||
| 共通 | 表示名 | アクティビティの表示名です。 | |
| エラー発生時に実行を継続 | アクティビティが例外をスローした場合でも、ワークフローを継続するかどうかを指定します。 | ||
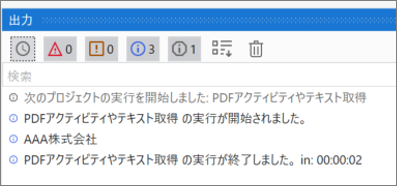
サンプルプロセス
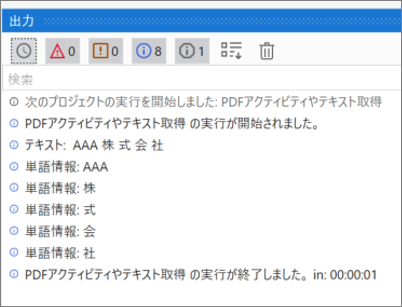
あらかじめ開いておいたPDFファイルのUI要素を指定して一部テキストを読み取り、読み取ったテキストデータと単語情報をログメッセージへ出力する。
・プロセス
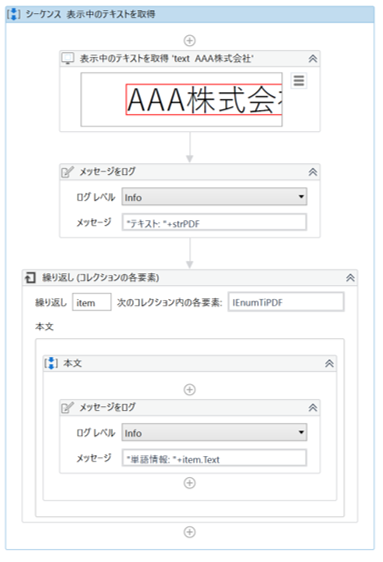
・表示中のテキストを取得
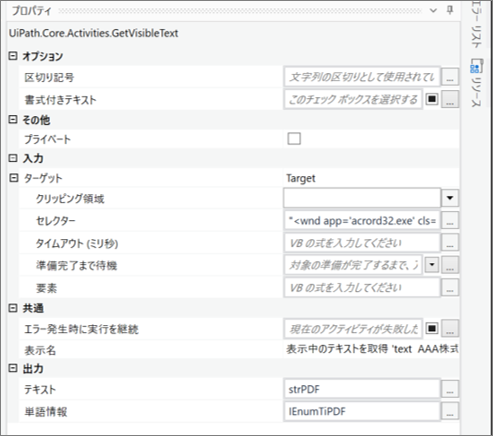
・表示中のテキストを取得のセレクター
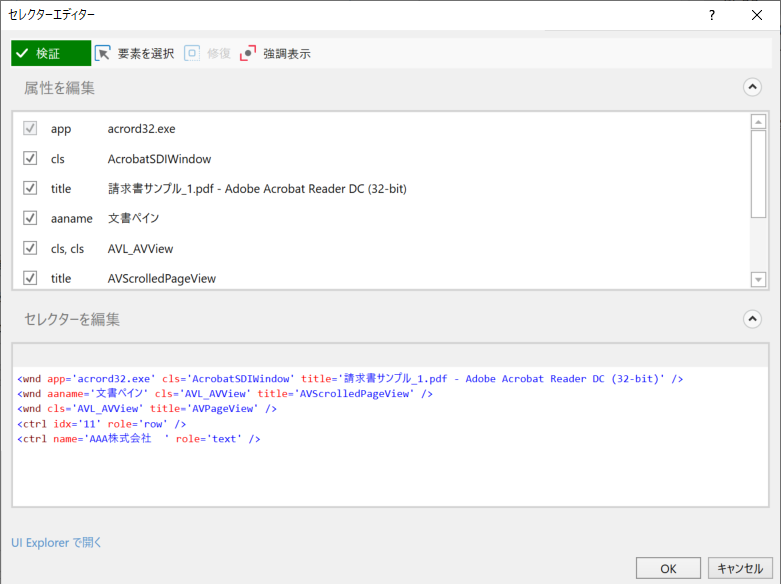
・繰り返し (コレクションの各要素)のプロパティ
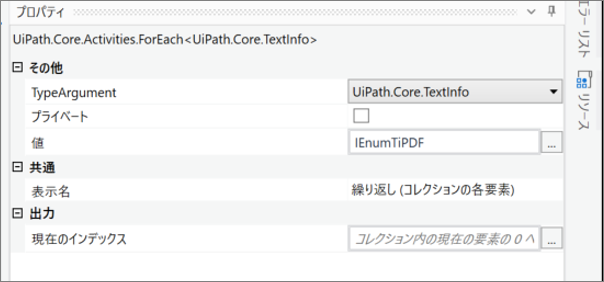
・変数の設定

・読み取り対象のPDF
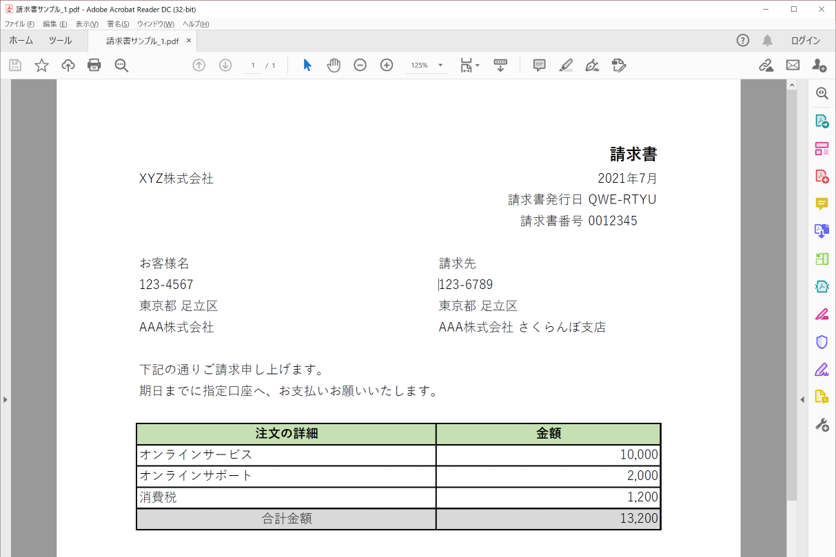
・実行結果のログ
アンカー ベース (Anchor Base)
PDF内で画面上の要素を特定できない場合は、他の要素や画像を目印として指定し、相対的な位置にある要素の値を取得する「アンカー ベース (Anchor Base)」のアクティビティを使用します。
「アンカー ベース (Anchor Base)」は、UI AUtomation > 要素 > 検出 にあります。
アンカー ベースの設定項目
| 設定場所 | 設定項目 | 設定内容 | |
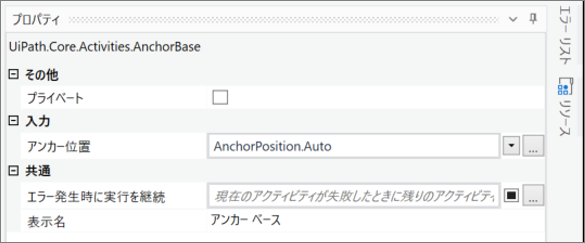
| [プロパティ] パネル内 | 入力 | アンカー位置 | コントロールが固定されているコンテナーの端を指定します。 |
| 共通 | 表示名 | アクティビティの表示名です。 | |
| エラー発生時に実行を継続 | アクティビティが例外をスローした場合でも、ワークフローを継続するかどうかを指定します。 | ||
| その他 | プライベート | オンにした場合、変数および引数の値が Verbose レベルでログに出力されなくなります。 | |
サンプルプロセス1
あらかじめ開いておいたPDFファイルのUI要素を指定して、相対位置にある一部テキストを読み取り、読み取ったテキストデータをログメッセージへ出力する。
・プロセス
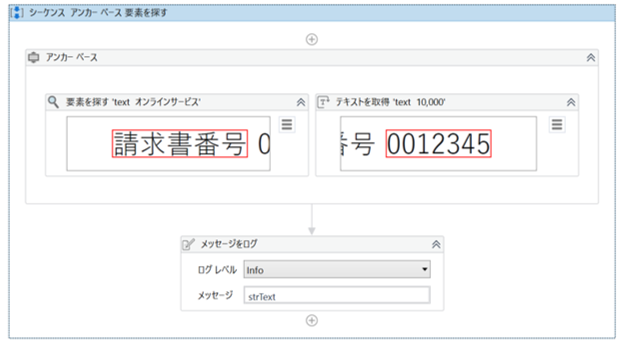
・「アンカー ベース」のプロパティ
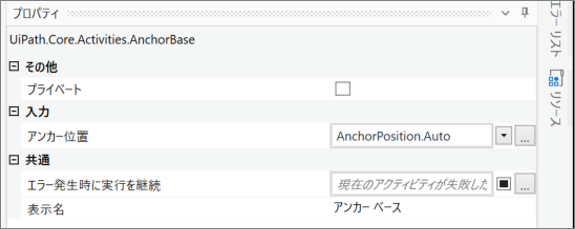
・「要素を探す」のプロパティ
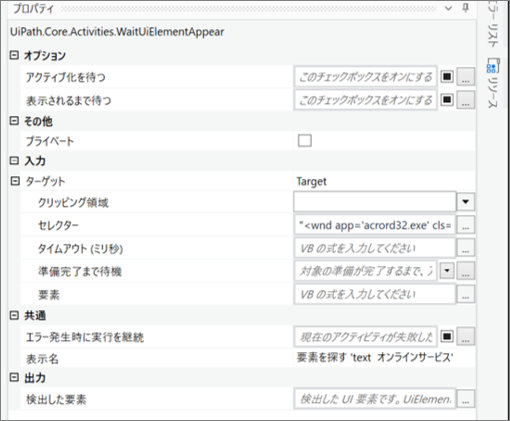
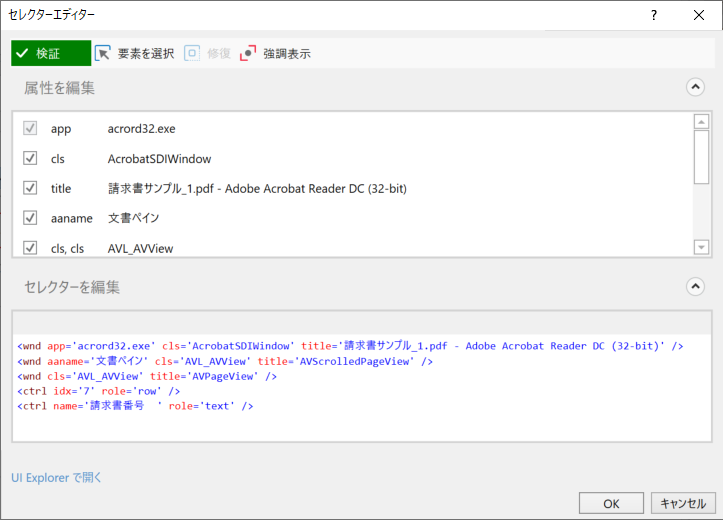
・「要素を探す」のセレクター
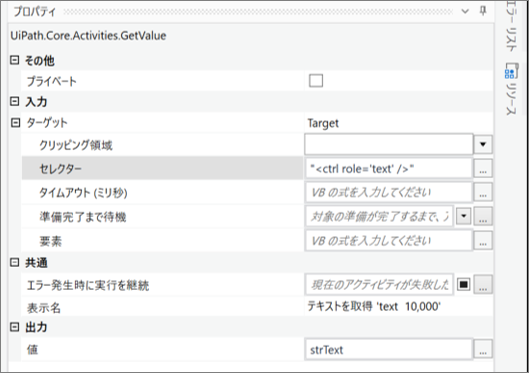
・「テキストを取得」のプロパティ
・変数

・読み取り対象のPDF
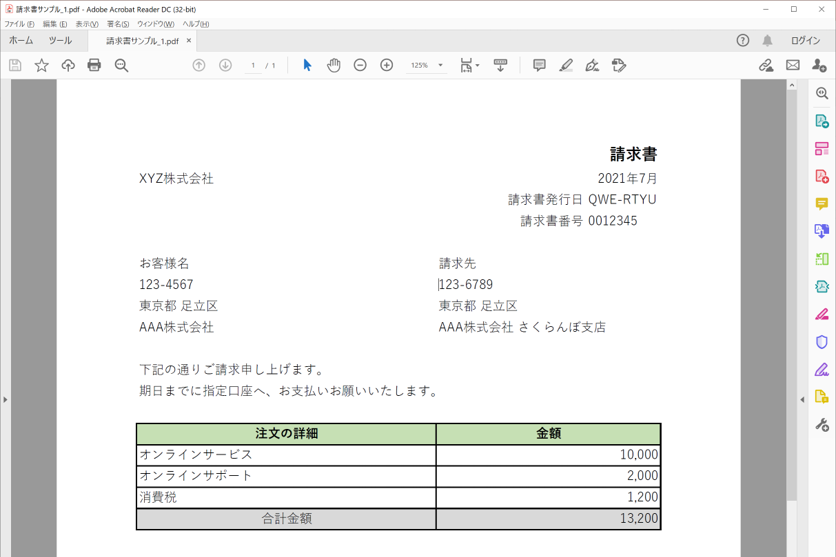
・実行結果のログ
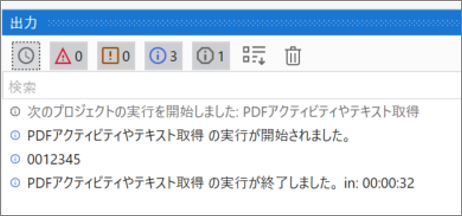
サンプルプロセス2
あらかじめ開いておいたPDFファイルの画像要素を指定して、相対位置にある一部テキストを読み取り、読み取ったテキストデータをログメッセージへ出力する。
・プロセス
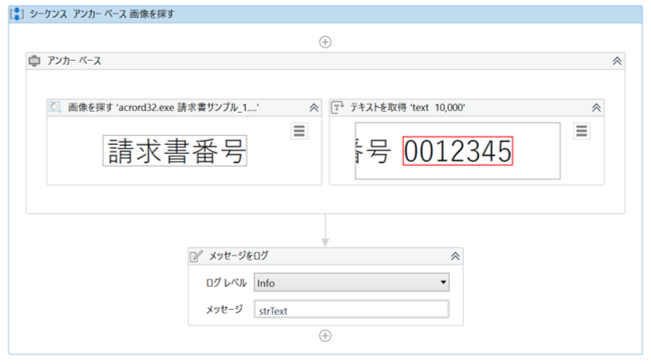
・「アンカー ベース」のプロパティ
・「画像を探す」のプロパティ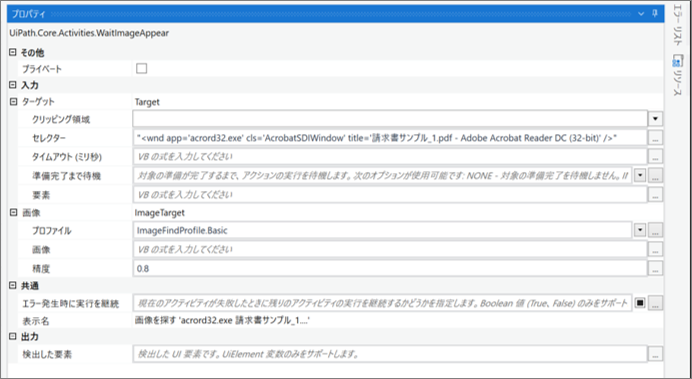
・「テキストを取得」のプロパティ
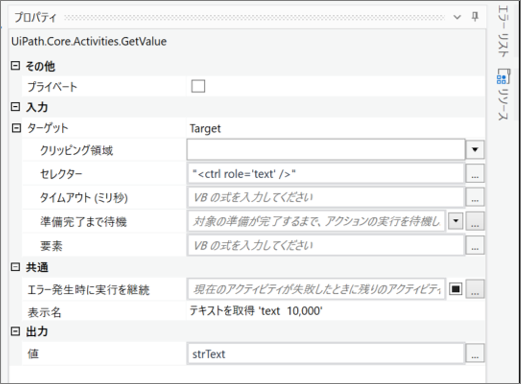
・変数

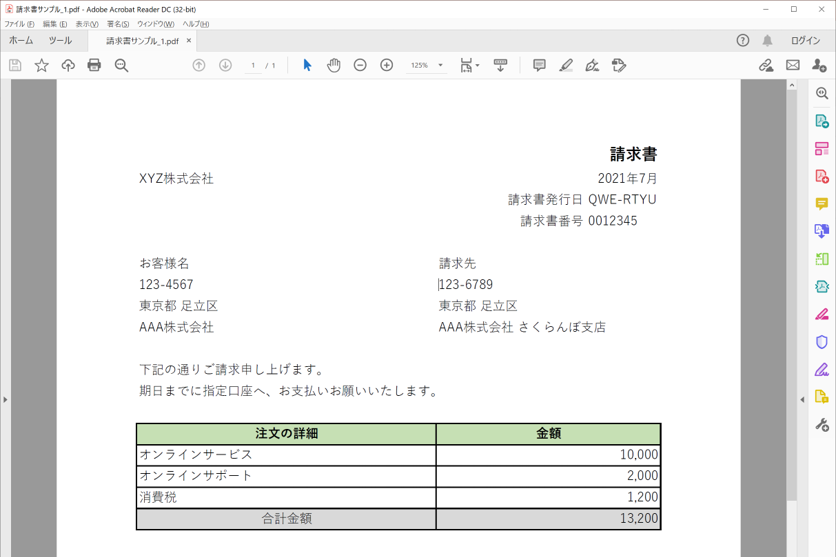
・読み取り対象のPDF
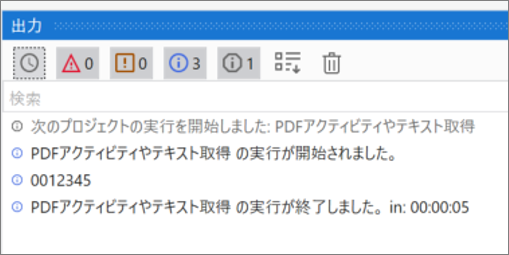
・実行結果のログ
CV テキストを取得(CV Get Text)
PDF内で画面上の要素を特定できない、アンカーベースの画像指定もできない場合は、AI Computer Visionを使って他の画像を目印として指定し、相対的な位置にある要素の値を取得する「CV テキストを取得(CV Get Text)」のアクティビティを使用します。
「CV テキストを取得(CV Get Text)」と「CV 画面スコープ (CV Screen Scope)」は、Compuer Vision 配下にあります。
CV テキストを取得の設定項目
| 設定場所 | 設定項目 | 設定内容 | |
| [プロパティ] パネル内 | 共通 | エラー発生時に実行を継続 | アクティビティが例外をスローした場合でも、ワークフローを継続するかどうかを指定します。 |
| 実行後の待機時間 | アクティビティ実行後した後の遅延時間 (ミリ秒) です。 | ||
| 実行前の待機時間 | アクティビティが何らかの操作の実行を開始するまでの遅延時間 (ミリ秒) です。 | ||
| 表示名 | アクティビティの表示名です。 | ||
| 入力 | 記述子 | 使用されるターゲットと各アンカーの画面上の座標 (ある場合)。 | |
| メソッド | テキストの取得に使用するメソッドを指定します。 | ||
| タイムアウト (ミリ秒) | エラーがスローされる前にアクティビティが実行されるまで待機する時間 (ミリ秒単位) を指定します。 | ||
| その他 | プライベート | オンにした場合、変数および引数の値が Verbose レベルでログに出力されなくなります。 | |
| オプション | あらかじめ更新 | オンの場合、Computer Vision による画面の分析が実行され、前回 [CV 画面スコープ] または [CV 更新] アクティビティを使用した後にユーザー インターフェイスが変更されている場合は、その変更をキャプチャします。 | |
| 出力 | 結果 | 変数に格納された取得テキスト。 | |
| 再利用可能な領域 | 入力領域 | 変数に格納されている別の CV アクティビティのターゲットを受信し、このアクティビティのターゲットとして使用します。 | |
| 出力領域 | このアクティビティのターゲットを Rectangle 変数として保存します。 | ||
CV 画面スコープの設定項目
| 設定場所 | 設定項目 | 設定内容 | |
| [プロパティ] パネル内 | 共通 | エラー発生時に実行を継続 | アクティビティが例外をスローした場合でも、ワークフローを継続するかどうかを指定します。 |
| 実行前の待機時間 | アクティビティが何らかの操作の実行を開始する前の遅延時間 (ミリ秒単位) です。 | ||
| 表示名 | アクティビティの表示名です。 | ||
| 入力 | CVメソッド | – | |
| ターゲット | クリッピング領域 | UiElement を基準とし、左、上、右、下の方向で、クリッピング四角形 (ピクセル単位) を定義します。 | |
| 要素 | 別のアクティビティから返される UiElement 変数を使用します。 | ||
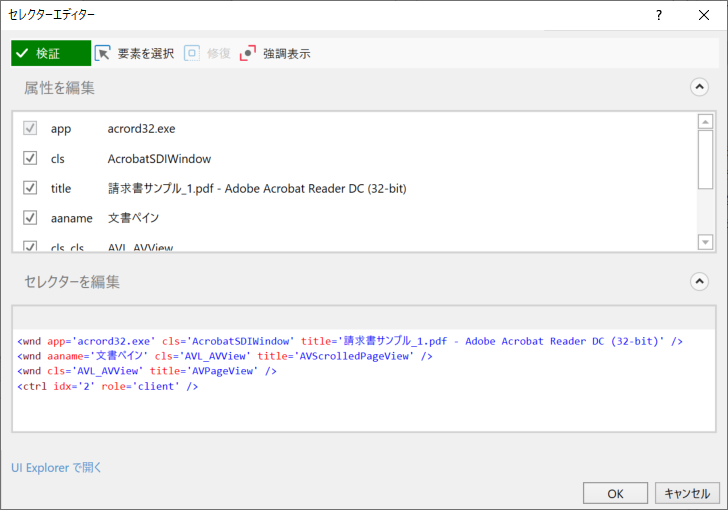
| セレクター | アクティビティの実行時に特定の UI 要素の検索に使用する Text プロパティです。 | ||
| タイムアウト(ミリ秒) | エラーがスローされるまでにアクティビティが待機する時間 (単位: ミリ秒) を指定します。 | ||
| 準備完了まで待機 | アクティビティを実行する前にターゲットが準備完了になるまで待機します。 | ||
| その他 | プライベート | オンにした場合、変数および引数の値が Verbose レベルでログに出力されなくなります。 | |
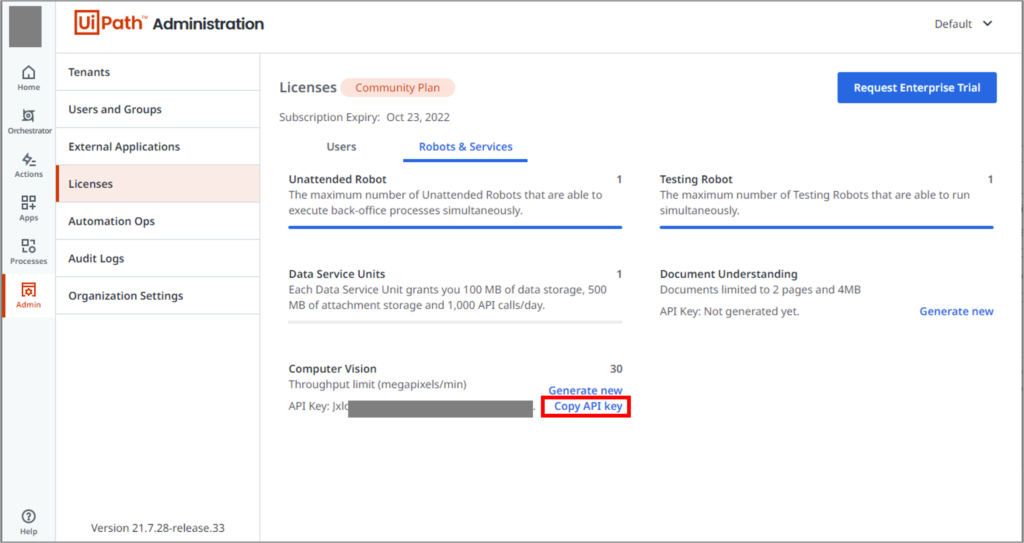
| サーバー (同期済み) | API キー | Computer Vision サーバーへのアクセスに必要な API キーです。 | |
| URL | Computer Vision サービスを実行するサーバーの URL。既定では、このプロパティは https://cv.uipath.com/ に設定されています 。 | ||
| ローカル サーバーを使用 | 選択すると、ローカル サーバーが分析に使用されます。 | ||
| アクティビティの本体 | 指定した画面 | 自動化するアプリケーションは、アクティビティの本体にある [画面上で指定] ボタンを使用することで、[CV 画面スコープ] アクティビティに指定できます。 | |
| 画面名 | ドロップダウンから画面の名前を選択し、rename ボタンをクリックして、名前を変更することもできます。 |
||
サンプルプロセス
あらかじめ開いておいたPDFファイルの画面を指定して、画面内の画像の相対位置にある一部テキストを読み取り、読み取ったテキストデータをログメッセージへ出力する。
・プロセス
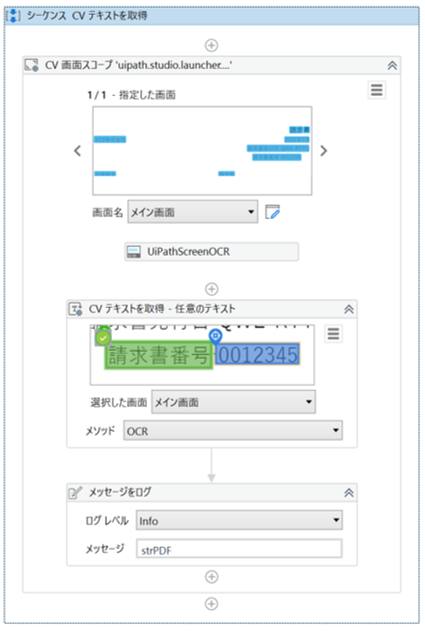
・「CV 画面スコープ」のプロパティ
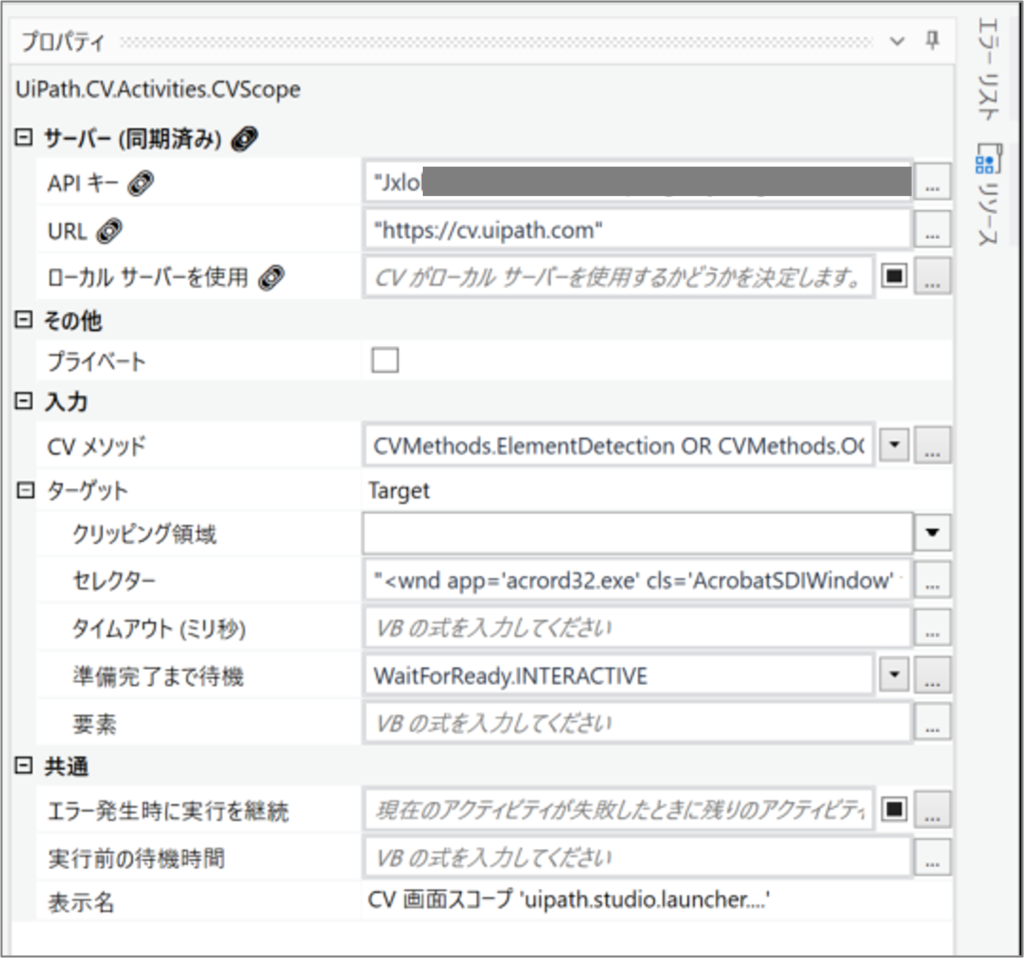
・「CV 画面スコープ」のセレクター
・「CV 画面スコープ」のAPIキー
・「UiPathScreenOCR」のプロパティ
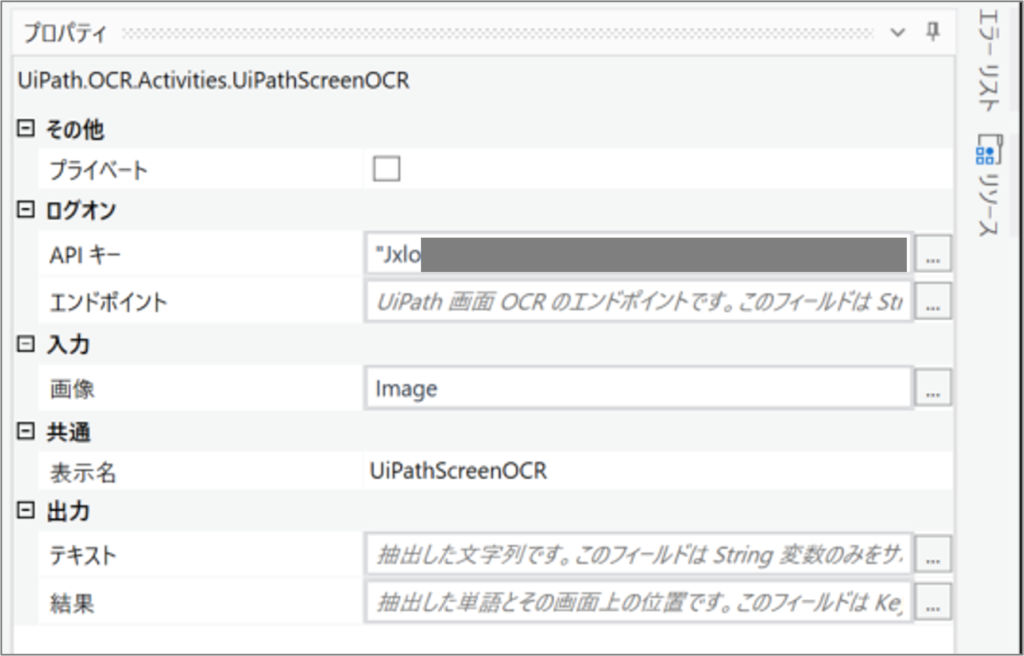
・「CV テキストを取得」のプロパティ
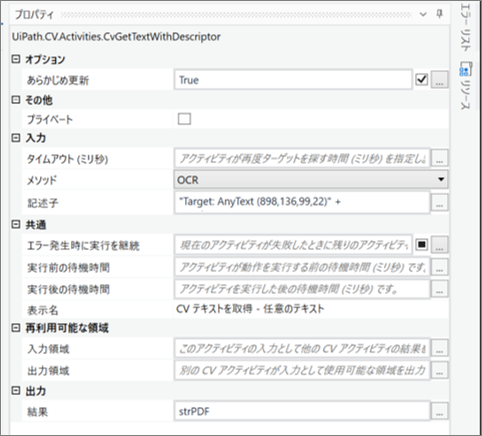
・変数

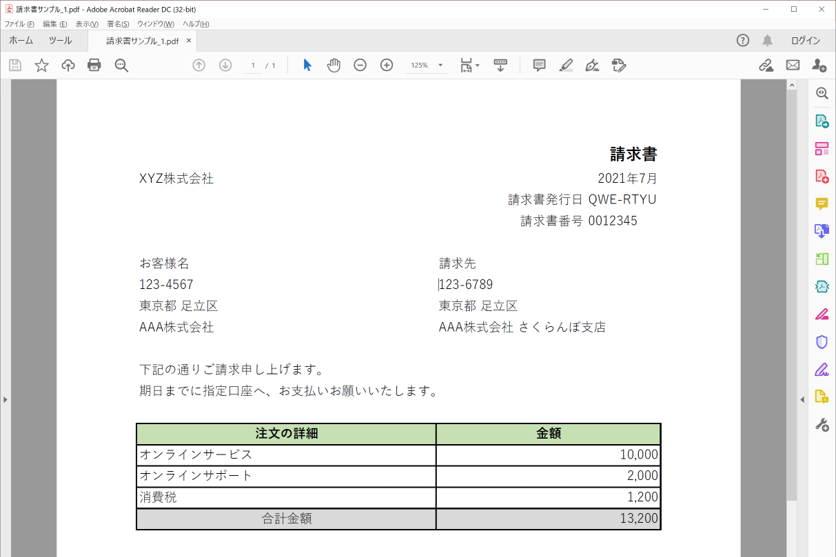
・読み取り対象のPDF
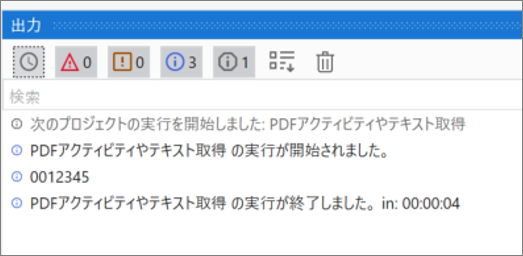
・実行結果のログ
まとめ
- PDFのアクティビティは、UiPath.PDF Activitiesパッケージをインストールすることで使用できる
- PDFの全テキストを抽出するアクティビティは、PDF のテキストを読み込み、フルテキストを取得、OCR で PDF を読み込み を使用する
- PDFの一部テキストを抽出するアクティビティは、テキストを取得、表示中のテキストを取得、アンカーベース、CV テキストを取得 を使用する。
関連記事 【UiPath】Udemyのオンラインコースでワンランク上のロボット作成技術を学ぶ
\教育訓練給付金対象講座なら受講料最大45万円給付/
*オンライン個別説明会&相談会への参加は無料
関連記事 現役SEエフペンがもしIT未経験からWebエンジニアを目指すならプログラミングスクール【ディープロ】を受講する









