
この記事では、UiPathのOCRを利用してPDFファイルのテキストデータを抽出する方法について、解説します。
システム開発,クラウド構築,サービス企画まで幅広い経験を持つITエンジニア。当ブログでは、UiPathや資格取得のノウハウを発信します。profile詳細 / twitter:@fpen17
OCR でテキストを取得(Get OCR Text)
OCRでPDFファイルのテキストデータを読み取るには、「OCR でテキストを取得(Get OCR Text)」とOCRのエンジンを使用します。
OCR でテキストを取得(Get OCR Text)の設定項目
| 設定場所 | 設定項目 | 設定内容 |
|---|---|---|
| 出力 | Text | 指定した UI 要素から抽出された文字列です。 |
| WordsInfo | 指定した UI 要素の中で見つかった各単語のスクリーン座標です。このフィールドでは TextInfo 変数のみサポートされています。 | |
| Misc | プライベート | オンにした場合、変数および引数の値が Verbose レベルでログに出力されなくなります。 |
| Target.Selector | アクティビティの実行時に特定の UI 要素の検索に使用する Text プロパティです。 | |
| Target.TimeoutMS | アクティビティの実行が完了するまで待機する時間をミリ秒で指定します。 | |
| Target.WaitForReady | アクションを実行する前に、ターゲットが準備完了になるまで待ちます。 | |
| Target.Element | 別のアクティビティから返される UiElement 変数を使用します。 | |
| Target.ClippingRegion | UiElement を基準とし、左、上、右、下の方向で、クリッピング四角形 (ピクセル単位) を定義します。 | |
| 共通 | 表示名 | アクティビティの表示名です。 |
| エラー発生時に実行を継続 | アクティビティが例外をスローした場合でも、ワークフローを継続するかどうかを指定します。 |
エンジンにTesseract OCRを使用
OCRのエンジンを「Tesseract OCRを使用」としてPDFファイルを読み取ります。
Tesseract OCRを使用の設定項目
| 設定場所 | 設定項目 | 設定内容 |
|---|---|---|
| オプション | 許可する文字 | OCR エンジンは、ここに指定した文字に従って、指定の文字列を抽出します。 |
| 拒否する文字 | OCR エンジンは、ここに指定した文字を考慮せずに、指定の文字列を抽出します。 | |
| Invert | このチェック ボックスをオンにした場合は、スクレイピングの前に UI 要素の色が反転します。 | |
| 言語 | OCR エンジンが UI 要素または画像から文字列を抽出する際に使用する言語です。 | |
| ExtractWords | このチェック ボックスをオンにした場合は、検出された各単語の画面上の位置が抽出されます。 | |
| プロファイル | OCR の読み取りを向上させる目的で、指定した画像または UI 要素の前処理プロファイルを選択します。 | |
| 拡大縮小 | 選択した UI 要素または画像の拡大縮小の倍率。 | |
| 出力 | テキスト | 抽出したテキストです。 |
| 結果 | 抽出された単語と画面上の位置が表示されます。 | |
| 入力 | 画像 | 処理対象の画像です。 |
| 共通 | 表示名 | アクティビティの表示名です。 |
| その他 | プライベート | オンにした場合、変数および引数の値が Verbose レベルでログに出力されなくなります。 |
サンプルプロセス
PDFの文字を読み取りログへ出力する。
・ワークフロー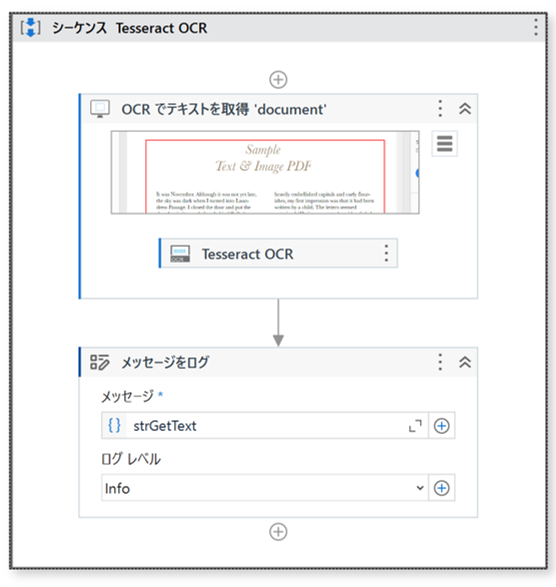
・対象のPDF
・「OCR でテキストを取得 ‘document’」のプロパティ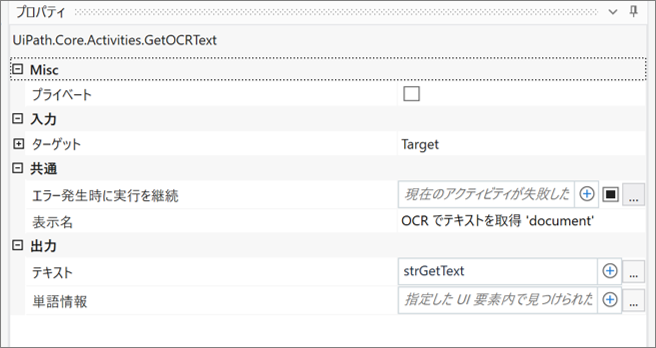
・「Tesseract OCR」のプロパティ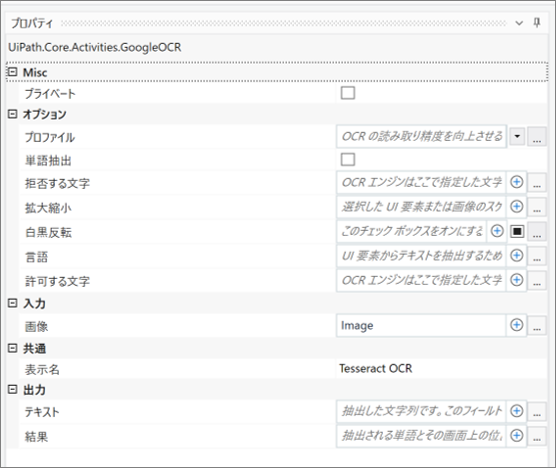
・実行結果

PDFの文字をログへ出力できているよ。
エンジンにUiPath 画面 OCRを使用
OCRのエンジンを「UiPath 画面 OCR」としてPDFファイルを読み取ります。
UiPath 画面 OCRの設定項目
| 設定場所 | 設定項目 | 設定内容 |
|---|---|---|
| 共通 | 表示名 | アクティビティの表示名です。 |
| 入力 | 画像 | 処理対象の画像です。 |
| ログオン | API キー | UiPath 画面 OCR へのアクセスに必要な API キーです。 |
| エンドポイント | UiPath 画面 OCRのエンドポイントです。 | |
| タイムアウト (ミリ秒) | サーバーからの応答があるまで待機する時間をミリ秒で指定します。 | |
| その他 | プライベート | オンにした場合、変数および引数の値が Verbose レベルでログに出力されなくなります。 |
| ローカル サーバーを使用 | ローカル サーバーを使用するかどうかを決定します。 | |
| 出力 | 結果 | 取得されたワードと画面上の位置です。 |
| Text | 抽出したテキストです。 |
サンプルプロセス
PDFの文字を読み取りログへ出力する。
・ワークフロー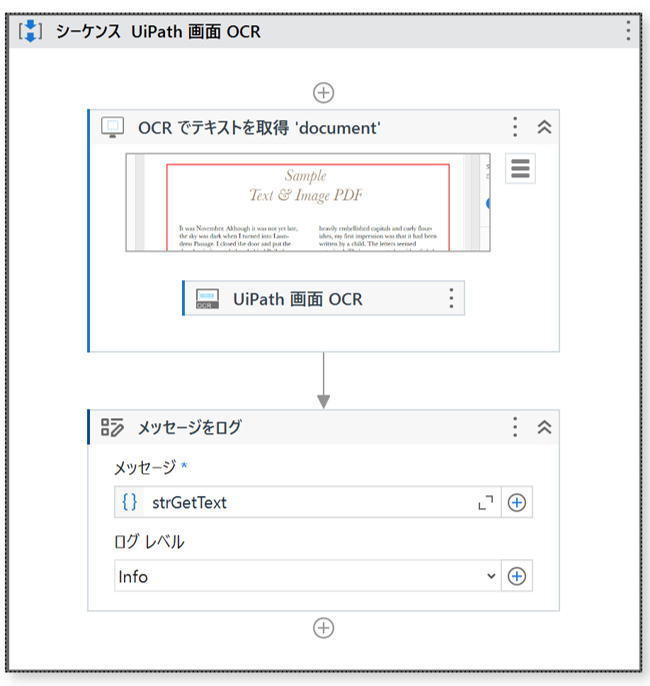
・OCR でテキストを取得 ‘document’ のプロパティ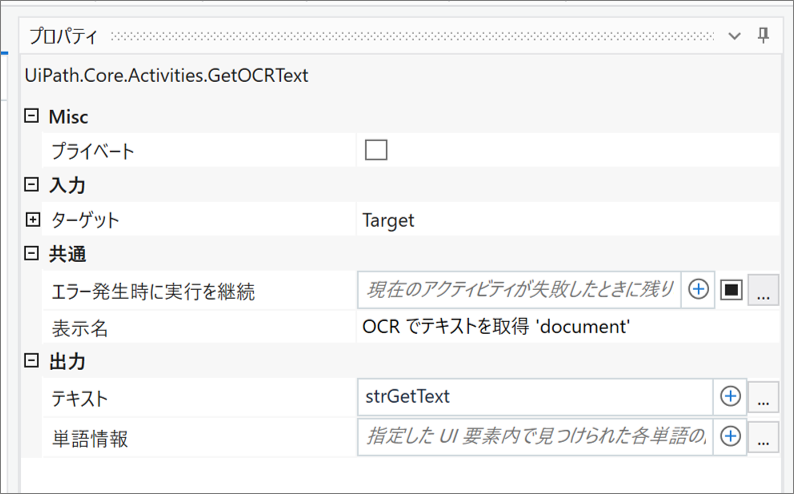
・UiPath 画面 OCR のプロパティ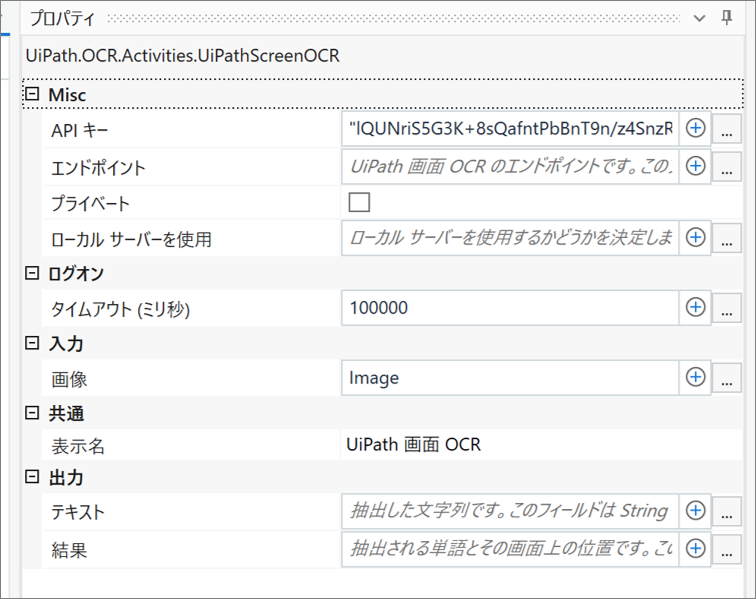
・変数
・読み取り対象のPDF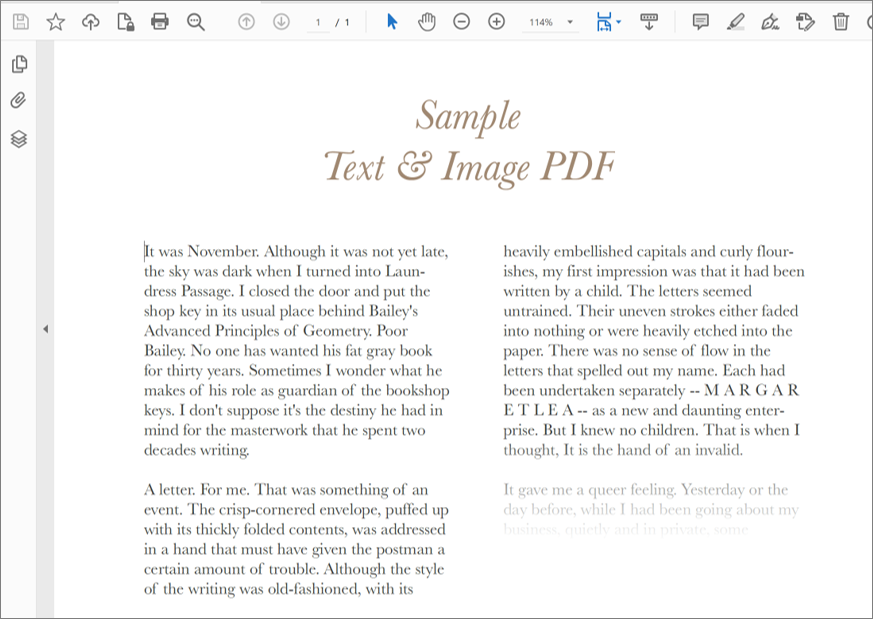
・実行結果のログ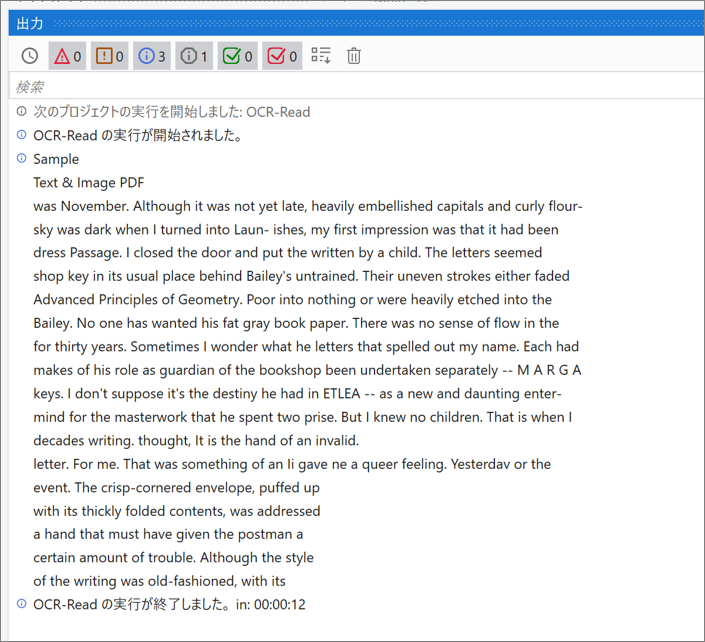
PDFの文字をログへ出力できているよ。
エンジンにOCR – 日本語、中国語、韓国語を使用
OCRのエンジンを「OCR – 日本語、中国語、韓国語」としてPDFファイルを読み取ります。
OCR – 日本語、中国語、韓国語の設定項目
| 設定場所 | 設定項目 | 設定内容 |
|---|---|---|
| 共通 | 表示名 | アクティビティの表示名です。 |
| 入力 | 画像 | 処理対象の画像です。 |
| ログオン | API キー | Document Understanding へのアクセスに必要な API キーです。 |
| エンドポイント | Document Understanding の API キーに関連付けられたエンドポイントです。 | |
| その他 | プライベート | オンにした場合、変数および引数の値が Verbose レベルでログに出力されなくなります。 |
| 出力 | 結果 | 抽出された単語と画面上の位置に関する情報を提供します。 |
| Text | 抽出したテキストです。 |
サンプルプロセス
PDFの文字を読み取りログへ出力する。
・ワークフロー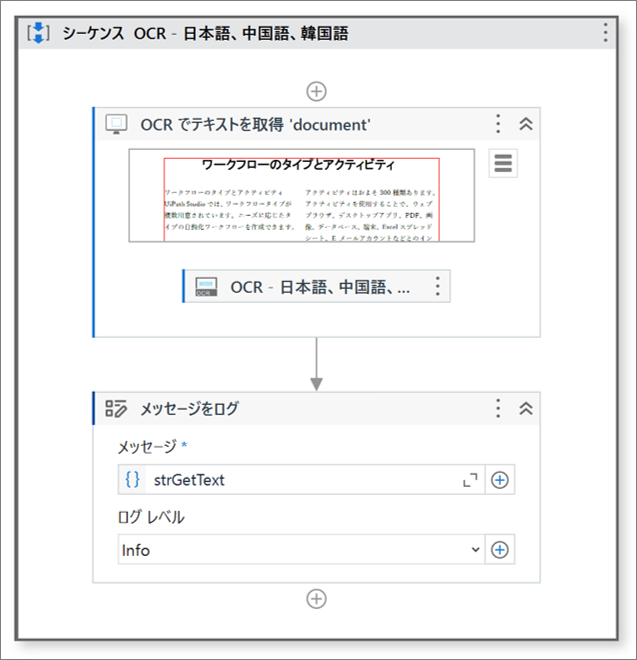
・OCR でテキストを取得 ‘document’のプロパティ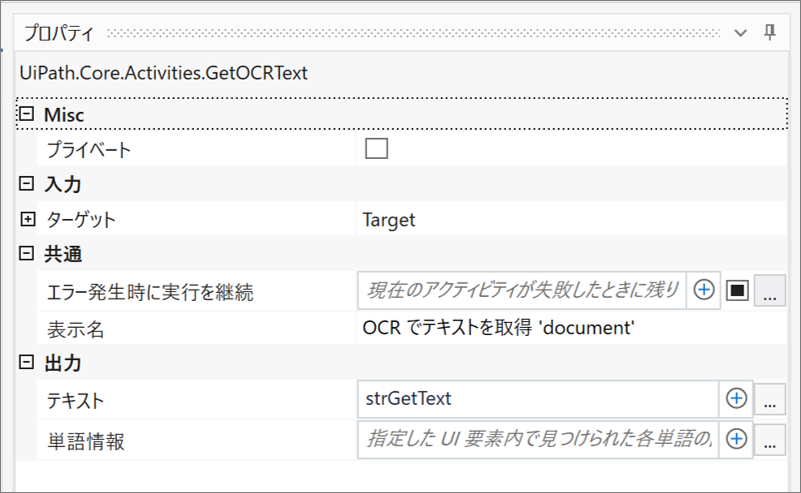
・OCR – 日本語、中国語、韓国語 のプロパティ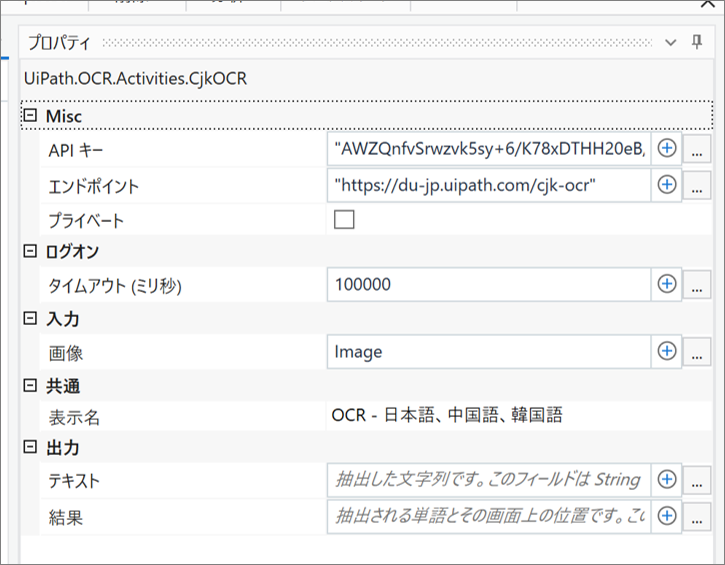
APIキーの取得は、Automation Cloudの「Admin → Licenses → Robots & Service → Computer Vision」のApi Keyから取得します
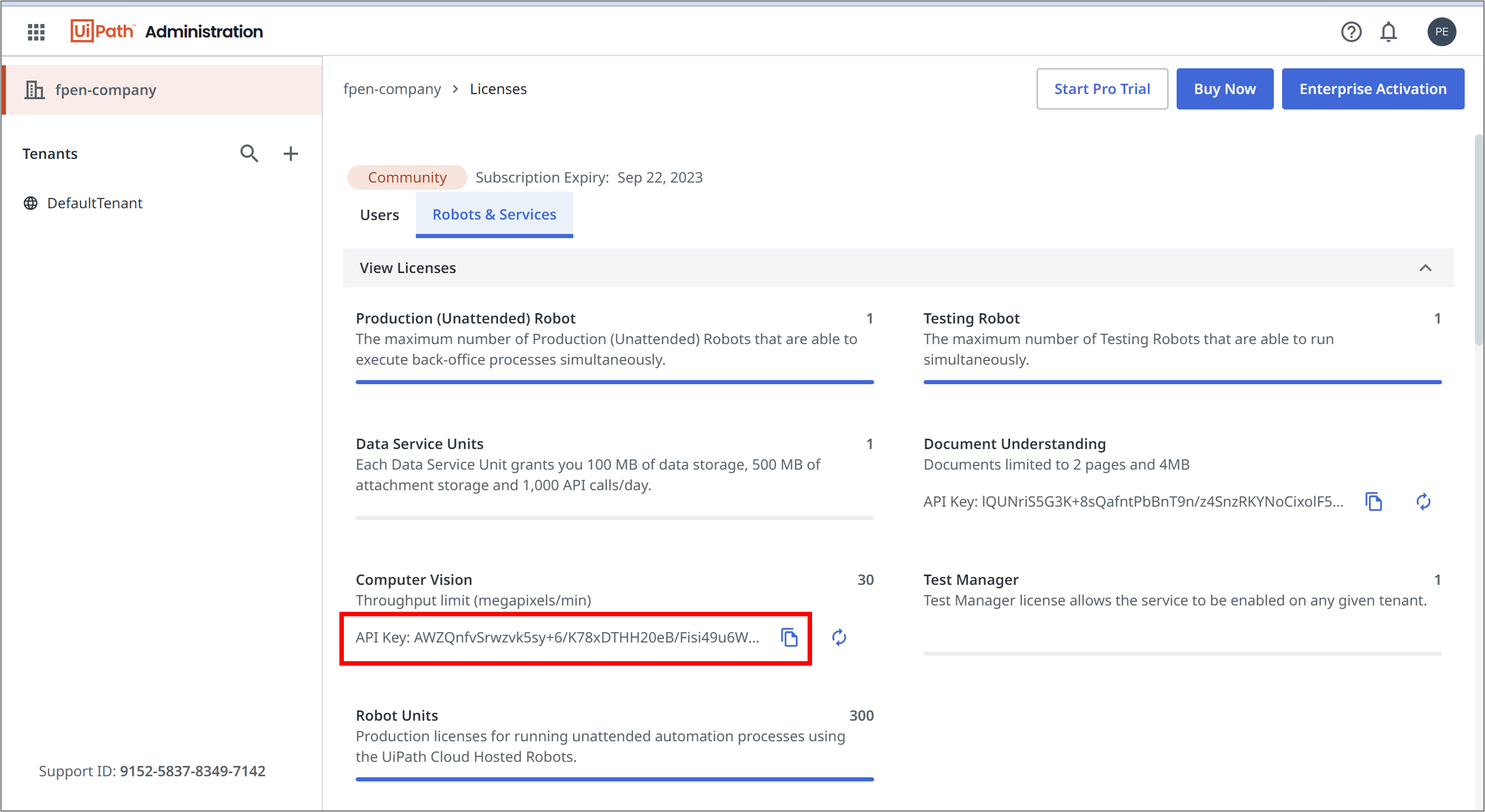
・変数
・読み取り対象のPDF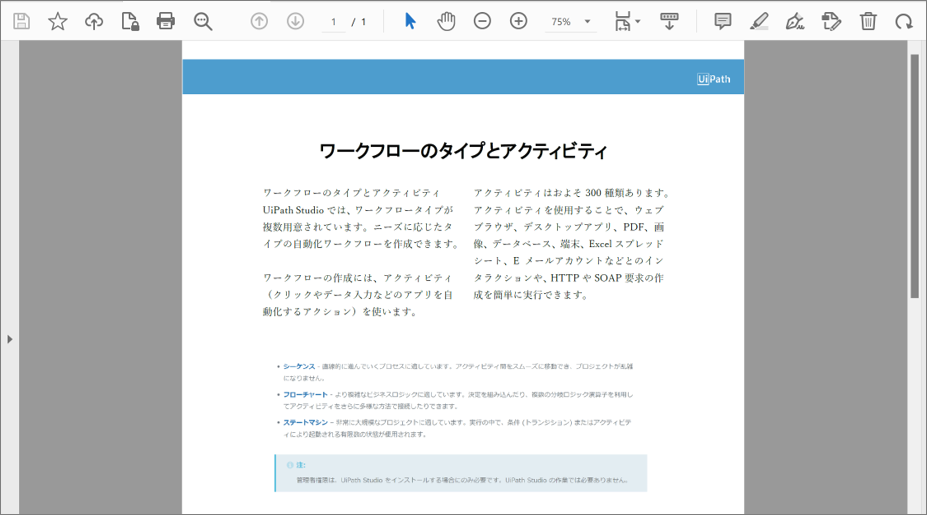
・実行結果のログ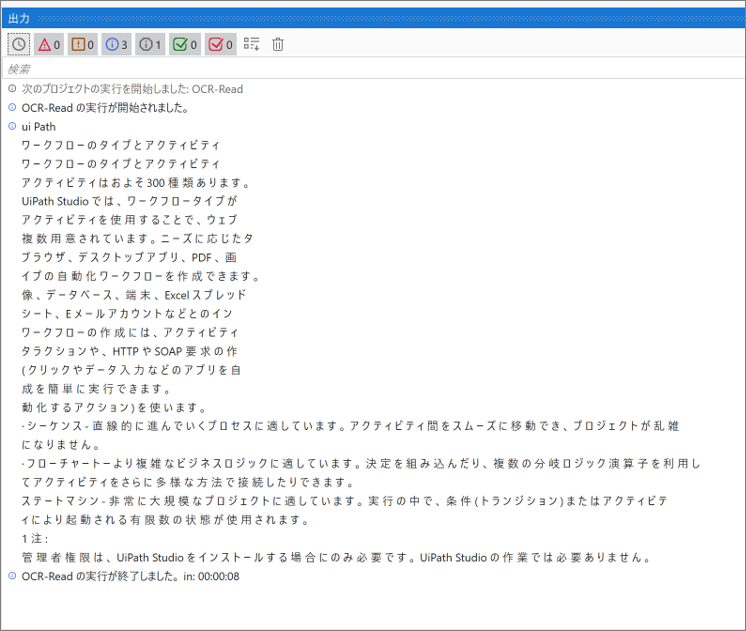
PDFの文字をログへ出力できているよ。
まとめ
- OCR でテキストを取得(Get OCR Text)と一つのエンジンを使用して、PDFのテキストを読み取る。
- 日本語の読み取りは、OCR – 中国語、日本語、韓国語 を使用する。
\教育訓練給付金対象講座なら受講料最大45万円給付/
*オンライン個別説明会&相談会への参加は無料
関連記事 現役SEエフペンがもしIT未経験からWebエンジニアを目指すならプログラミングスクール【ディープロ】を受講する









